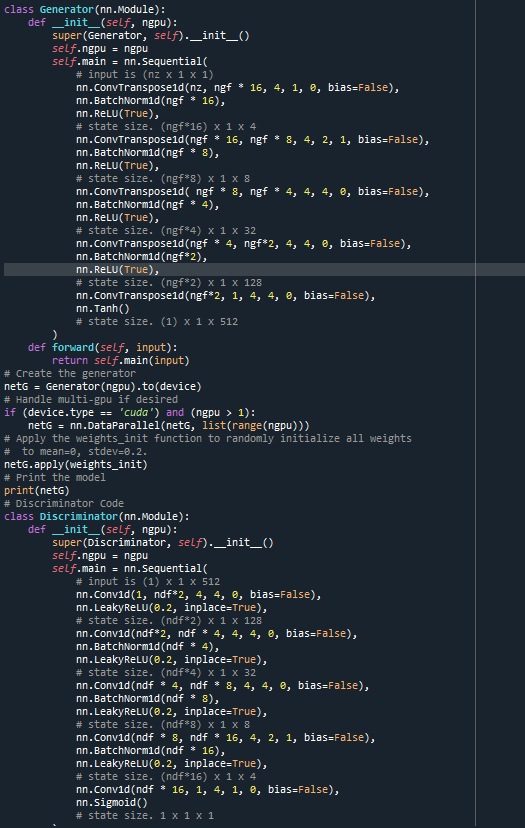
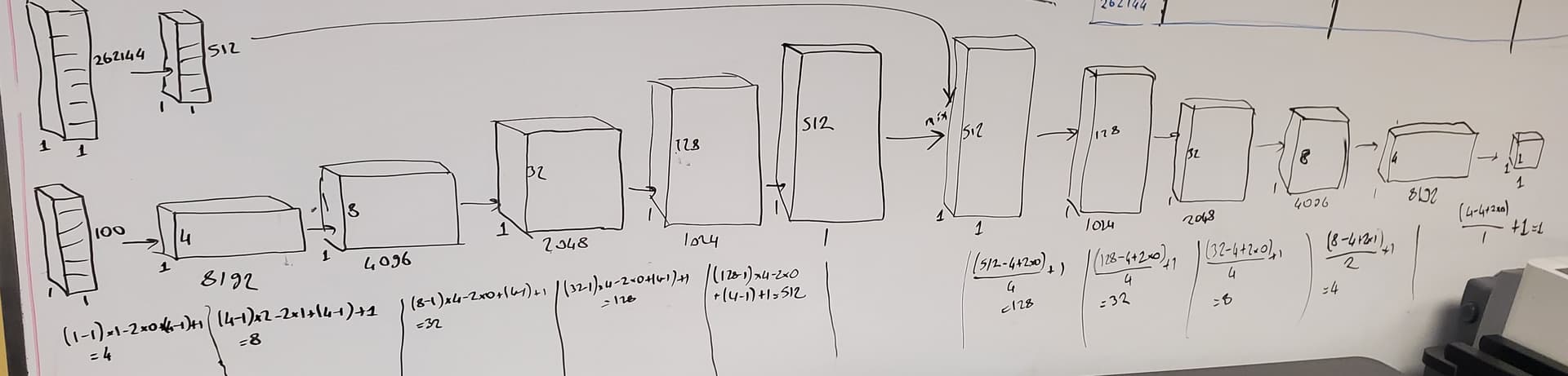
Thank you for your response. I see your help all over the blog posts and you are doing awesome work! For the sake of better understanding, I drew the model here. I am not totally sure the correctness of this as this is my first time doing 1d conv:
Then I think I get errors in the discriminator part.
Here is the error I get:
I really did not understand this error. And also here is my code again:
batch_size = 512
nz = 100
ngf = 512
ndf = 512
num_epochs = 512
lr = 0.0002
beta1 = 0.5
ngpu = 1
dataloader = torch.utils.data.DataLoader(a11n, batch_size=batch_size,
shuffle=True, num_workers=workers)
device = torch.device(“cuda:0” if (torch.cuda.is_available() and ngpu > 0) else “cpu”)
real_batch = next(iter(dataloader))
custom weights initialization called on netG and netD
def weights_init(m):
classname = m.class.name
if classname.find(‘Conv’) != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find(‘BatchNorm’) != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
Generator Code
class Generator(nn.Module):
def init(self, ngpu):
super(Generator, self).init()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nz x 1 x 1)
nn.ConvTranspose1d(nz, ngf * 16, 4, 1, 0, bias=False),
nn.BatchNorm1d(ngf * 16),
nn.ReLU(True),
# state size. (ngf16) x 4 x 1
nn.ConvTranspose1d(ngf * 16, ngf * 8, 4, 2, 1, bias=False),
nn.BatchNorm1d(ngf * 8),
nn.ReLU(True),
# state size. (ngf8) x 8 x 1
nn.ConvTranspose1d( ngf * 8, ngf * 4, 4, 4, 0, bias=False),
nn.BatchNorm1d(ngf * 4),
nn.ReLU(True),
# state size. (ngf4) x 32 x 1
nn.ConvTranspose1d(ngf * 4, ngf2, 4, 4, 0, bias=False),
nn.BatchNorm1d(ngf2),
nn.ReLU(True),
# state size. (ngf2) x 128 x 1
nn.ConvTranspose1d(ngf*2, ngf, 4, 4, 0, bias=False),
nn.Tanh()
# state size. (512) x 1 x 1
)
def forward(self, input):
return self.main(input)
Create the generator
netG = Generator(ngpu).to(device)
Apply the weights_init function to randomly initialize all weights
to mean=0, stdev=0.2.
netG.apply(weights_init)
Discriminator Code
class Discriminator(nn.Module):
def init(self, ngpu):
super(Discriminator, self).init()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (1) x 1 x 512
nn.Conv1d(1, ndf2, 4, 4, 0, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf2) x 1 x 128
nn.Conv1d(ndf2, ndf * 4, 4, 4, 0, bias=False),
nn.BatchNorm1d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf4) x 1 x 32
nn.Conv1d(ndf * 4, ndf * 8, 4, 4, 0, bias=False),
nn.BatchNorm1d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf8) x 1 x 8
nn.Conv1d(ndf * 8, ndf * 16, 4, 2, 1, bias=False),
nn.BatchNorm1d(ndf * 16),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf16) x 1 x 4
nn.Conv1d(ndf * 16, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
# state size. 1 x 1 x 1
)
def forward(self, input):
return self.main(input)