I’m running the code of Mean Teacher where the teacher is updated via EMA.
The Teacher’s state_dicts of 10 continuous EMA updates are saved (marked as Tn-1, Tn-2, …, Tn-10), and I want to check the distance between the output of Tn and Tn-10:
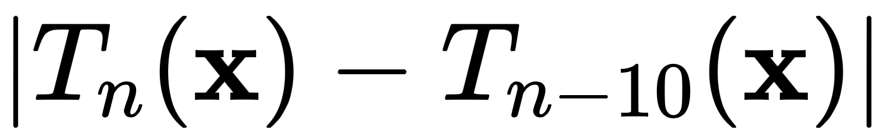
When I use traditional DataParallel, the value is usually 0.3~0.7.
But when I use AMP+DDP on single device but multi GPUs, the value is 0.01 ~ 0.1.
And also, I tried AMP+DataParallel and AMP+DDP on single device and single GPU, the value back to 0.3~0.7.
So it looks like something goes different from usual when DDP is apply on multi GPUs.
My code looks like:
# Model Initialize
scaler = amp.GradScaler()
student_model = Model().cuda()
teacher_model = Model().cuda()
teacher_dict = student_model.state_dict().copy()
student_model = nn.SyncBatchNorm.convert_sync_batchnorm(student_model)
# student_model = nn.DataParallel(student_model, device_ids = gpu_ids)
student_model = DDP(student_model, device_ids = [local_rank])
teacher_model = nn.SyncBatchNorm.convert_sync_batchnorm(teacher_model)
# teacher_model = nn.DataParallel(teacher_model, device_ids = gpu_ids)
teacher_model = DDP(teacher_model, device_ids = [local_rank])
loss_fn = nn.SmoothL1Loss().cuda()
opt = torch.optim.Adam([{"params":[p for p in list(student_model.parameters()) if p.requires_grad]}], lr=lr, betas=(0.5, 0.999))
# Training
teacher_dict_list = []
teacher_dict_prev = None # Tn-10, at the beginning is None
for epoch in range(num_epochs):
for data in trainloader:
images, labels = data
images = images.cuda()
labels = labels.cuda()
with amp.autocast():
preds = student_model(images)
loss = loss_fn(preds, labels)
scaler.scale(loss).backward()
scaler.step(opt)
opt.zero_grad()
t = teacher_dict.copy()
for k, v in t.items():
t[k] = t[k].cpu() # store on cpu memory, or the cuda memory would overflow
teacher_dict_list.append(t) # store Tn-1
# EMA update teacher_dict
for k, v in student_model.module.state_dict().items():
if k.find('num_batches_tracked') == -1:
teacher_dict[k] = 0.999 * teacher_dict[k] + 0.001 * v
# we have stored 10 teacher's state_dicts
if len(teacher_dict_list) == 10:
teacher_dict_prev = teacher_dict_list[0] # pick Tn-10
del(teacher_dict_list[0])
if teacher_dict_prev is None:
continue
else:
teacher_model.module.load_state_dict(teacher_dict) # load the newest state_dict
with torch.no_grad():
with amp.autocast():
output_cur = teacher_model(images)
teacher_model.module.load_state_dict(teacher_dict_prev) # load the old state_dict
with torch.no_grad():
with amp.autocast():
output_prev = teacher_model(images)
print(torch.abs(output_cur - output_prev).max())
scaler.update()
The code above is a simplified version, the structure is the same. To some reason, I can’t post all my code for you to reproduce the problem.
So, the printed value is 0.3 ~ 0.7 (which i think should be correct) at the setting of:
- DataParallel w/o AMP on single device and multi GPUs
- DataParallel with AMP on single device and multi GPUs
- DDP with AMP on single device and single GPU
but it becomes much smaller (0.01 ~ 0.1) on DDP with AMP on single device and multi GPUs.