hi, guys
Below is REINFORCE update rule.
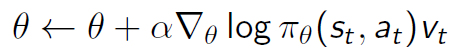
Instead of log probability, the reinforcement learning example uses the probability to compute the gradient. Is it correct ?
hi, guys
Below is REINFORCE update rule.
Instead of log probability, the reinforcement learning example uses the probability to compute the gradient. Is it correct ?
The gradient of the log of the probability (in the case of the multinomial distribution that’s used in the example) is negative the reciprocal of the probability, which is what you’ll find in the multinomial function’s backward definition.
Thanks for your reply.