A. ENV
- centos 7
- Linux localhost.localdomain 3.10.0-693.el7.x86_64 #1 SMP Tue Aug 22 21:09:27 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
- gcc version 9.3.1 20200408 (Red Hat 9.3.1-2) (GCC)
- Python 3.8.5 (default, Sep 4 2020, 07:30:14)
- libtorch 1.8.1 CPU version
- x86_64 4CPU
B. TEST CODE
torch::jit::script::Module module;
module = torch::jit::load(argv[1]);
std::vectortorch::jit::IValue inputs;
at::Tensor input = torch::ones({1, 300, 40});
inputs.push_back(input);
for (int i=0; i < num; i++) {
b = time_get_ms();
std::cout << "module forward begin" << std::endl;
at::Tensor output = module.forward(inputs).toTensor();
e = time_get_ms();
d = e - b;
std::cout << "forward output size : " << output.numel() << ", No." << i <<" forward time : " << d << std::endl;
usleep(100 * 1000); // sleep 100ms
}
avg_duration = total_duration / num ;
std::cout << "AVG forward time : " << avg_duration << std::endl;
C. Performance
-
When I commented out the “usleep(100 * 1000)” code, I found that latency is good.
-
When I keep the “usleep(100 * 1000)” code, I find that latency is bad .
-
The above phenomenon is inevitable .
D. Question
- Why do I get worse performance when I execute the “usleep(100 * 1000)” code ?
- Especially in the multi-threaded scenario (for example. at::set_num_threads(4)), it is more serious ;
- The performance data is in the comments.
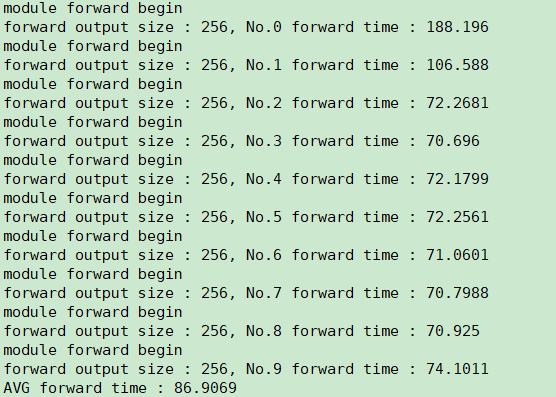
When I commented out the “usleep(100 * 1000)” code, I found that latency was good. As shown in the picture below :
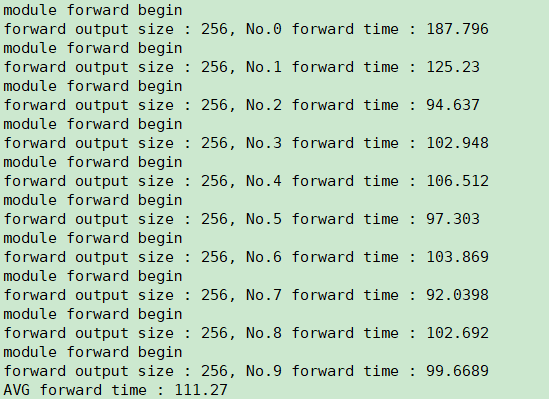
When I keep the “usleep(100 * 1000)” code, I find that latency is bad . As shown in the picture below :
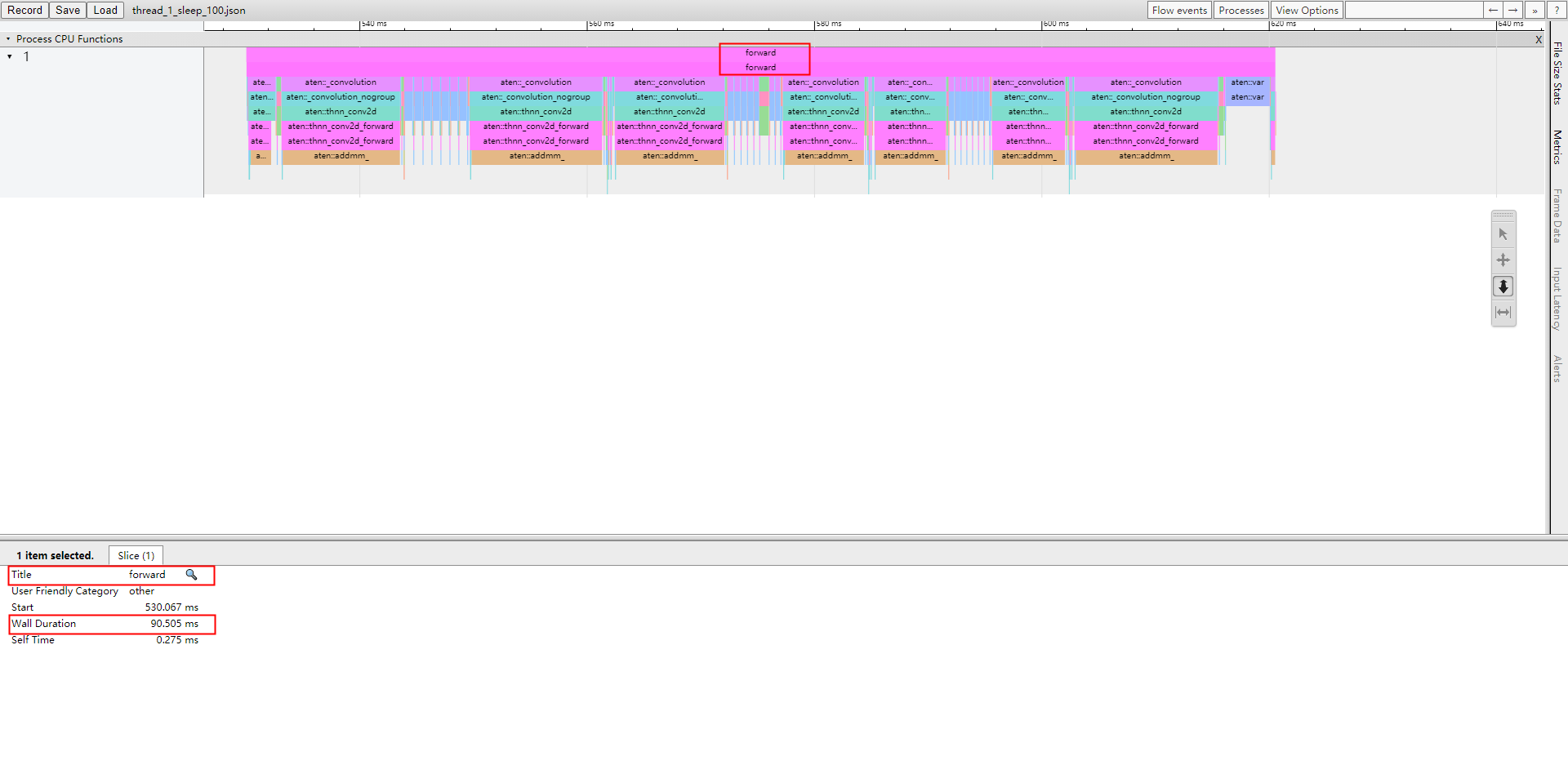
I have done the profiling , as shown in the figure below
no sleep 100ms
I have done the profiling , as shown in the figure below :
sleep 100ms
I’m not sure I understand the question correctly. If you let the main thread sleep, the loop would be paused and the execution of the next iteration would be delayed. What is the expectation?
The forward time is the duration of forwarding execution, not the start time . When I execute usleep() function in the test code, the duration of each forwarding operation is longer.
LOL, I’ve solved this problem, and the reason is CPU frequency conversion .
A. RESEON :
- When I commented out the “usleep(100 * 1000)” code, The CPU is in high performance state;you can check the ‘CPU MHz’ by running the command : lscpu
- When I keep the “usleep(100 * 1000)” code,the CPU will switch between high performance and low performance which slows down the calculation. so the duration of function ‘module.forward’ is getting longer.
B. HOW CAN I FIND THIS QUESTION ?
-
I do a lot of experiments. I am confuesed about the phenomenon, it is very strange. There’s no reason to suspect that the ‘module.forward’ function has a bug because of running ‘usleep(100*1000)’;
-
When the experiment is in operation, I check the CPU state and I found that the CPU MHz is changging. 
 Suddenly inspiration came, and I remember this will slow down the calculation, because I’ve had similar problems before
Suddenly inspiration came, and I remember this will slow down the calculation, because I’ve had similar problems before
-
So I run the command : cat /sys/devices/system/cpu/cpu1/cpufreq/scaling_governor
The output is : powersave
-
Run the command : sudo cpupower -c all frequency-set -g performance
-
Rerun the test code, it works.
1 Like
That’s great debugging and thanks for sharing it here!