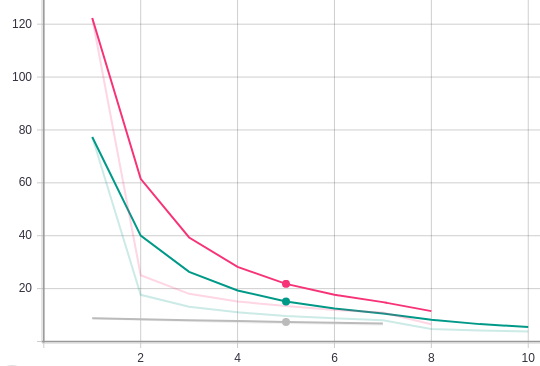
I am working on basic hyper-parameter tuning where my parameters are Learning rate [0.03], Batch [64, 88].
Individual training with [0.03, 64] parameter gives green loss curve, on the other hand for [0.03, 88] parameter gives pink loss curve. This seems correct as the pattern of loss curve remain same just their is shift because of the batch size.
While doing combined training one after the other, for [0.03, 64] parameter i still get green loss curve but for [0.03,88] parameter i am getting the Gray curve (which is at the bottom of image shown). I think this is because gradients learned form Run1 are not being deleted as a result causing Run2 to start with very low loss value.
But before starting Run2 i have reinitialised the instance of Optimiser, Model, Scheduler and after completion of Run 1 i have even deleted all the previous gradients using model.zero_grad(), optimizer.zero_grad(). Can somebody please help!!