Hello
Someone solve this problem please?
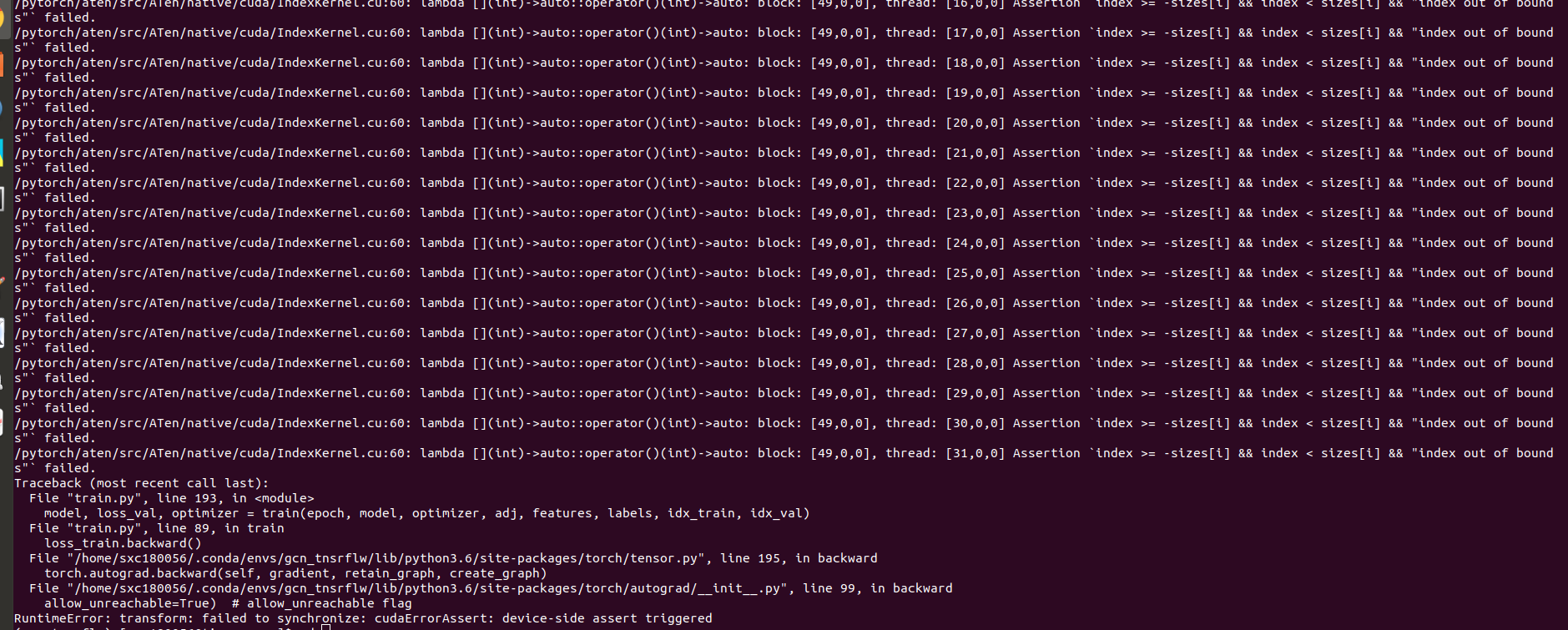
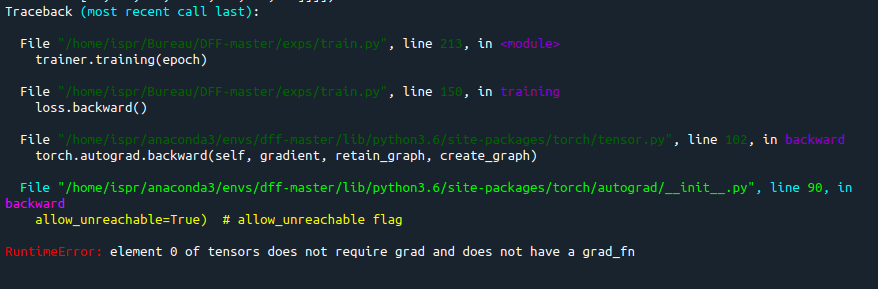
During the training of this code i have a problem in loss.backward()
Thank you
###########################################################################
Created by: Yuan Hu
Email: huyuan@radi.ac.cn
Copyright (c) 2019
###########################################################################
import os
import copy
import time
import numpy as np
import torch
import torch.utils.data as data
import torchvision.transforms as transform
from torch.nn.parallel.scatter_gather import gather
import encoding.utils as utils
from encoding.nn import BatchNorm2d
from encoding.parallel import DataParallelModel, DataParallelCriterion
from losses import EdgeDetectionReweightedLosses, EdgeDetectionReweightedLosses_CPU
from datasets import get_edge_dataset
from models import get_edge_model
from option import Options
from tqdm import tqdm
from torch.autograd import Variable
torch_ver = torch.version[:3]
if torch_ver == ‘0.3’:
from torch.autograd import Variable
class Trainer():
def init(self, args):
self.args = args
args.log_name = str(args.checkname)
self.logger = utils.create_logger(args.log_root, args.log_name)
self.logger.info(args)
# data transforms
input_transform = transform.Compose([
transform.ToTensor(),
transform.Normalize([.485, .456, .406], [.229, .224, .225])])
# dataset
data_kwargs = {'transform': input_transform, 'base_size': args.base_size,
'crop_size': args.crop_size, 'logger': self.logger,
'scale': args.scale}
trainset = get_edge_dataset(args.dataset, split='train', mode='train',
**data_kwargs)
testset = get_edge_dataset(args.dataset, split='val', mode='val',
**data_kwargs)
# dataloader
kwargs = {'num_workers': args.workers, 'pin_memory': True} \
if args.cuda else {}
self.trainloader = data.DataLoader(trainset, batch_size=args.batch_size,
drop_last=True, shuffle=True, **kwargs)
self.valloader = data.DataLoader(testset, batch_size=args.batch_size,
drop_last=False, shuffle=False, **kwargs)
self.nclass = trainset.num_class
# model
model = get_edge_model(args.model, dataset=args.dataset,
backbone=args.backbone,
norm_layer=torch.nn.BatchNorm2d,
crop_size=args.crop_size,
)
self.logger.info(model)
# optimizer using different LR
if args.model == 'dff': # dff
params_list = [{'params': model.pretrained.parameters(), 'lr': args.lr},
{'params': model.ada_learner.parameters(), 'lr': args.lr*10},
{'params': model.side1.parameters(), 'lr': args.lr*10},
{'params': model.side2.parameters(), 'lr': args.lr*10},
{'params': model.side3.parameters(), 'lr': args.lr*10},
{'params': model.side5.parameters(), 'lr': args.lr*10},
{'params': model.side5_w.parameters(), 'lr': args.lr*10}]
else: # casenet
assert args.model == 'casenet'
params_list = [{'params': model.pretrained.parameters(), 'lr': args.lr},
{'params': model.side1.parameters(), 'lr': args.lr*10},
{'params': model.side2.parameters(), 'lr': args.lr*10},
{'params': model.side3.parameters(), 'lr': args.lr*10},
{'params': model.side5.parameters(), 'lr': args.lr*10},
{'params': model.fuse.parameters(), 'lr': args.lr*10}]
optimizer = torch.optim.SGD(params_list,
lr=args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
self.criterion = EdgeDetectionReweightedLosses_CPU()
self.model, self.optimizer = model, optimizer
# using cuda
if args.cuda:
self.model = DataParallelModel(self.model).cuda()
self.criterion = DataParallelCriterion(self.criterion).cuda()
# finetune from a trained model
if args.ft:
args.start_epoch = 0
checkpoint = torch.load(args.ft_resume)
if args.cuda:
self.model.module.load_state_dict(checkpoint['state_dict'], strict=False)
else:
self.model.load_state_dict(checkpoint['state_dict'], strict=False)
self.logger.info("=> loaded checkpoint '{}' (epoch {})".format(args.ft_resume, checkpoint['epoch']))
# resuming checkpoint
if args.resume:
if not os.path.isfile(args.resume):
raise RuntimeError("=> no checkpoint found at '{}'" .format(args.resume))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
if args.cuda:
self.model.module.load_state_dict(checkpoint['state_dict'])
else:
self.model.load_state_dict(checkpoint['state_dict'])
if not args.ft:
self.optimizer.load_state_dict(checkpoint['optimizer'])
self.logger.info("=> loaded checkpoint '{}' (epoch {})".format(args.resume, checkpoint['epoch']))
# lr scheduler
self.scheduler = utils.LR_Scheduler(args.lr_scheduler, args.lr, args.epochs, len(self.trainloader), logger=self.logger, lr_step=args.lr_step)
def training(self, epoch):
self.model.train()
tbar = tqdm(self.trainloader)
# tbar = self.trainloader
train_loss = 0.
train_loss_all = 0.
for i, (image, target) in enumerate(tbar):
self.scheduler(self.optimizer, i, epoch)
self.optimizer.zero_grad()
outputs = self.model(image.float())
loss = self.criterion(outputs, target)
loss.backward()
self.optimizer.step()
train_loss += loss.item()
train_loss_all += loss.item()
if i == 0 or (i+1) % 20 == 0:
train_loss = train_loss / min(20, i + 1)
self.logger.info('Epoch [%d], Batch [%d],\t train-loss: %.4f' % (
epoch + 1, i + 1, train_loss))
train_loss = 0.
self.logger.info('-> Epoch [%d], Train epoch loss: %.3f' % (
epoch + 1, train_loss_all / (i + 1)))
if not self.args.no_val:
# save checkpoint every 20 epoch
filename = "checkpoint_%s.pth.tar"%(epoch+1)
if epoch % 19 == 0 or epoch == args.epochs-1:
utils.save_checkpoint({
'epoch': epoch + 1,
'state_dict': self.model.module.state_dict(),
'optimizer': self.optimizer.state_dict(),
}, self.args, filename)
def validation(self, epoch):
self.model.eval()
tbar = tqdm(self.valloader, desc='\r')
# tbar = self.valloader
val_loss = 0.
val_loss_all = 0.
for i, (image, target) in enumerate(tbar):
if torch_ver == "0.3":
image = Variable(image, volatile=True)
else:
with torch.no_grad():
outputs = self.model(image.float())
loss = self.criterion(outputs, target)
val_loss += loss.item()
val_loss_all += loss.item()
if i == 0 or (i+1) % 20 == 0:
val_loss = val_loss / min(20, i + 1)
self.logger.info('Epoch [%d], Batch [%d],\t val-loss: %.4f' % (
epoch + 1, i + 1, val_loss))
val_loss = 0.
self.logger.info('-> Epoch [%d], Val epoch loss: %.3f' % (
epoch + 1, val_loss_all / (i + 1)))
if name == “main”:
with torch.no_grad():
args = Options().parse()
torch.manual_seed(args.seed)
trainer = Trainer(args)
trainer.logger.info(['Starting Epoch:', str(args.start_epoch)])
trainer.logger.info(['Total Epoches:', str(args.epochs)])
for epoch in range(args.start_epoch, args.epochs):
trainer.training(epoch)
if not args.no_val:
trainer.validation(epoch)