Hello. I am newbie for PyTorch.
I think I fall in love with PyTorch these days, but I don’t know why XD.
I coded softmax classifier. But I am not sure it is trained correctly.
I get weird accuracy and loss values from the plot.
My model code is as follows:
import numpy as np
import torch
use_cuda = torch.cuda.is_available()
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class embedding_classifier(nn.Module):
def __init__(self, input_shape, num_classes):
super(embedding_classifier, self).__init__()
self.input_shape = input_shape
self.num_classes = num_classes
## softmax classifier
fc1 = nn.Linear(in_features=self.input_shape, out_features=1024, bias=True)
relu1 = nn.ReLU()
dropout1 = nn.Dropout(p=0.5)
fc2 = nn.Linear(in_features=1024, out_features=1024, bias=True)
relu2 = nn.ReLU()
dropout2 = nn.Dropout(p=0.5)
out = nn.Linear(in_features=1024, out_features=self.num_classes)
self.fc_module = nn.Sequential(
#layer1
fc1,
relu1,
dropout1,
#layer2
fc2,
relu2,
dropout2,
#output
out
)
if use_cuda:
self.fc_module = self.fc_module.cuda()
def forward(self, input_data):
out = self.fc_module(input_data)
out = F.softmax(out, dim=1)
return out
My training code is as follows:
## Load Packages
import sys, os
sys.path.append(os.path.abspath(os.path.dirname(__file__)))
sys.path.append(os.path.abspath(os.path.dirname(os.path.abspath(os.path.dirname(__file__)))))
sys.path.append(os.path.join(os.path.abspath(os.path.dirname(os.path.abspath(os.path.dirname(__file__)))), 'utils'))
sys.path.append(os.path.join(os.path.abspath(os.path.dirname(os.path.abspath(os.path.dirname(__file__)))), 'architecture'))
import cv2
import torch
use_cuda = torch.cuda.is_available()
import pickle
import argparse
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from torch.utils.data import TensorDataset, DataLoader
from architecture.embedding_learner_pytorch import embedding_classifier
## Define custom dataloader
def custom_dataloader(x, y, batch_size):
if batch_size > len(y):
batch_size = len(y)
tensor_x = torch.tensor(x)
tensor_y = torch.tensor(y, dtype=torch.long)
if use_cuda:
tensor_x = tensor_x.cuda()
tensor_y = tensor_y.cuda()
# one-hot label to class
tensor_y = torch.argmax(tensor_y, dim=1)
my_tensor_dataset = TensorDataset(tensor_x, tensor_y)
return DataLoader(my_tensor_dataset, batch_size=batch_size, shuffle=True)
## Do train
def main(args):
## Set epoch and batch_size
EPOCHS = args['epochs']
BATCH_SIZE = args['batch_size']
##Load face embeddings
embedding_data = pickle.loads(open(args['input_embedding_path'], 'rb').read())
print("[INFO] embedding data has been loaded...")
input_embeddings = np.array(embedding_data['embeddings'])
## Encode the labels
sklearn_label_encoder = LabelEncoder()
labels = sklearn_label_encoder.fit_transform(embedding_data['names'])
num_classes = len(np.unique(labels))
labels = labels.reshape(-1, 1)
one_hot_encoder = OneHotEncoder(categories='auto')
labels = one_hot_encoder.fit_transform(labels).toarray()
## Set model
model = embedding_classifier(input_shape=input_embeddings.shape[1], num_classes=num_classes)
## define loss
criterion = torch.nn.CrossEntropyLoss()
## define optimizer
optimizer = torch.optim.Adam(model.parameters())
## Create K-Fold
cross_validation = KFold(n_splits=5, random_state=31, shuffle=True)
## Initialize list of training information
history = {'train_acc': [], 'val_acc': [], 'train_loss': [], 'val_loss': []}
## Do training
cv_idx = 0
for train_idx, valid_idx in cross_validation.split(input_embeddings):
cv_idx += 1
print([f'[INFO] {cv_idx}-th cross validation start...'])
X_train, X_val, y_train, y_val = input_embeddings[train_idx], input_embeddings[valid_idx], labels[train_idx], labels[valid_idx]
## Set train Data Loader
train_data_loader = custom_dataloader(x=X_train, y=y_train, batch_size=BATCH_SIZE)
## Set validation Data Loader
valid_data_loader = custom_dataloader(x=X_val, y=y_val, batch_size=BATCH_SIZE)
for epoch in range(EPOCHS):
train_loss = 0.0
train_acc = 0.0
val_loss = 0.0
val_acc = 0.0
for i, data in enumerate(train_data_loader):
x, y = data
## grad init
optimizer.zero_grad()
## forward propagation
model_output = model(x)
## calculate loss
loss = criterion(model_output, y)
## back propagation
loss.backward()
## weight update
optimizer.step()
## calculate trainig loss and accuracy
train_loss += loss.item()
train_preds = torch.argmax(model_output, dim=1)
train_acc += train_preds.eq(y).float().mean().cpu().numpy()
## delete some variables for memory issue
del loss
del model_output
## Print training and validation summary
with torch.no_grad():
for j, val_data in enumerate(valid_data_loader):
val_x, val_y = val_data
val_output = model(val_x)
v_loss = criterion(val_output, val_y)
val_loss += v_loss.item()
## calculate trainig accuracy
val_preds = torch.argmax(val_output, dim=1)
val_acc += val_preds.eq(val_y).float().mean().cpu().numpy()
# print("val_loss: ", val_loss)
# print("val_acc: ", val_acc)
epoch_train_accuracy = train_acc / len(train_data_loader)
epoch_train_loss = train_loss / len(train_data_loader)
epoch_val_accuracy = val_acc / len(valid_data_loader)
epoch_val_loss = val_loss / len(valid_data_loader)
history['train_acc'].append(epoch_train_accuracy)
history['train_loss'].append(epoch_train_loss)
history['val_acc'].append(epoch_val_accuracy)
history['val_loss'].append(epoch_val_loss)
print("{}-th cross validation | epoch: {}/{} | training loss: {:.4f} | training acc: {:.4f} | val loss: {:.4f}, val acc: {:.4f}".format(
cv_idx, epoch+1, EPOCHS, epoch_train_loss, epoch_train_accuracy, epoch_val_loss, epoch_val_accuracy))
## Save the pytorch embedding classifier
torch.save(model.state_dict(), args["model_save_path"])
## Save label encoder
f = open(args["encoded_label_save_path"], "wb")
f.write(pickle.dumps(sklearn_label_encoder))
f.close()
## Plot performance figure
plt.figure(1)
ax1 = plt.subplot(211)
ax1.plot(history['train_acc'])
ax1.plot(history['val_acc'])
ax1.set_title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epochs')
ax1.legend(['train', 'test'], loc='best')
# Summary history for loss
ax2 = plt.subplot(212)
ax2.plot(history['train_loss'])
ax2.plot(history['val_loss'])
ax2.set_title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
ax2.legend(['train', 'test'], loc='best')
plt.savefig(args['figure_save_path'], dpi=300)
plt.show()
if __name__ == "__main__":
ap = argparse.ArgumentParser()
ap.add_argument("--input_embedding_path", default='/home/gbkim/gb_dev/insightface_MXNet/insightface/face_identification/face_bank/embeddings_info2.pickle')
ap.add_argument("--epochs", default=50, type=int, help="Epochs for training.")
ap.add_argument("--batch_size", default=4, type=int, help="Batch size for model training.")
ap.add_argument('--model_save_path', default="/home/gbkim/gb_dev/insightface_MXNet/insightface/face_identification/model/pytorch_embedding_classifier/embedding_classifier.pth", help="path of the model to be saved.")
ap.add_argument('--encoded_label_save_path', default="/home/gbkim/gb_dev/insightface_MXNet/insightface/face_identification/model/pytorch_embedding_classifier/label.pickle", help="path of the label encoder to be saved.")
ap.add_argument("--figure_save_path", default="/home/gbkim/gb_dev/insightface_MXNet/insightface/face_identification/model/pytorch_embedding_classifier/result_figure.png")
args = vars(ap.parse_args())
main(args)
I get this result as follows:
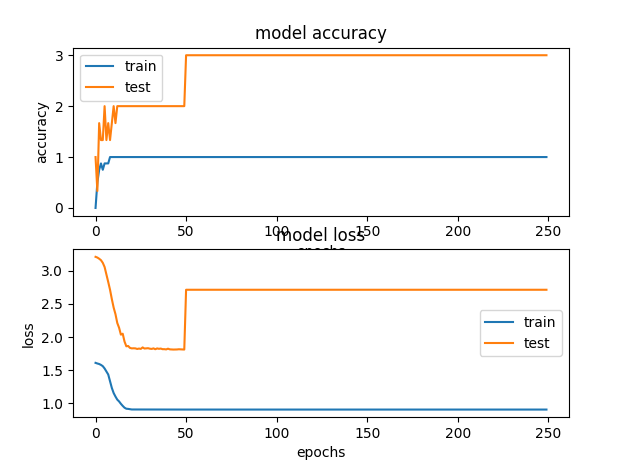
Could you guys help me?
