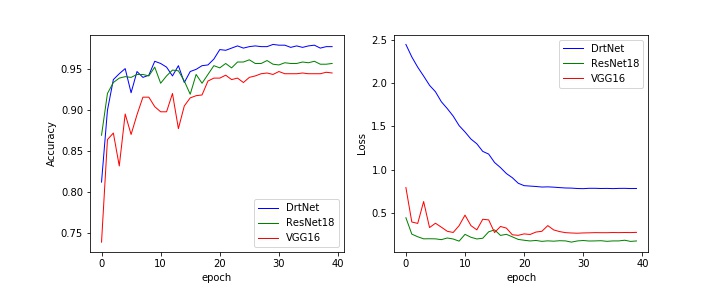
def main():
# 训练集图片读取
class TrainDataset(Dataset):
def __init__(self, label_list, transform=None, target_transform=None, loader=default_loader):
imgs = []
for index, row in label_list.iterrows():
imgs.append((row['img_path'], row['labels']))
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index):
filename, label = self.imgs[index]
img = self.loader(filename)
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
# 验证集图片读取
class ValDataset(Dataset):
def __init__(self, label_list, transform=None, target_transform=None, loader=default_loader):
imgs = []
for index, row in label_list.iterrows():
imgs.append((row['img_path'], row['labels']))
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index):
filename, label = self.imgs[index]
img = self.loader(filename)
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
# 测试集图片读取
class TestDataset(Dataset):
def __init__(self, label_list, transform=None, target_transform=None, loader=default_loader):
imgs = []
for index, row in label_list.iterrows():
imgs.append((row['img_path'], row['labels']))
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index):
filename, label = self.imgs[index]
img = self.loader(filename)
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
# 数据增强:在给定角度中随机进行旋转
class FixedRotation(object):
def __init__(self, angles):
self.angles = angles
def __call__(self, img):
return fixed_rotate(img, self.angles)
def fixed_rotate(img, angles):
angles = list(angles)
angles_num = len(angles)
index = random.randint(0, angles_num - 1)
return img.rotate(angles[index])
# 训练函数
def train(train_loader, model, criterion, optimizer, epoch):
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
acc = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (images, target) in enumerate(train_loader):
# measure data loading
data_time.update(time.time() - end)
result = []
for temp in target:
temp1 = temp.replace("'", "")
temp2 = temp1.replace(",", "")
temp3 = temp2.replace(" ", "")
temp3 = [int(m) for m in temp3]
for j in range(len(temp3)):
if temp3[j] == 1:
l = j
result.append(l)
result1 = np.array(result)
result2 = torch.from_numpy(result1)
# print(result2)
image_var = torch.tensor(images).cuda(async=True)
label = torch.tensor(result2).cuda(async=True)
# compute y_pred
y_pred = model(image_var)
loss = criterion(y_pred, label)
# measure accuracy and record loss
prec, PRED_COUNT = accuracy(y_pred.data, result2, topk=(1, 1))
losses.update(loss.item(), images.size(0))
acc.update(prec, PRED_COUNT)
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Accuray {acc.val:.3f} ({acc.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time, data_time=data_time, loss=losses, acc=acc))
# 验证函数
def validate(val_loader, model, criterion):
batch_time = AverageMeter()
losses = AverageMeter()
acc = AverageMeter()
# switch to evaluate mode
model.eval()
end = time.time()
for i, (images, target) in enumerate(val_loader):
result = []
for temp in target:
temp1 = temp.replace("'", "")
temp2 = temp1.replace(",", "")
temp3 = temp2.replace(" ", "")
temp3 = [int(m) for m in temp3]
for j in range(len(temp3)):
if temp3[j] == 1:
l = j
result.append(l)
result1 = np.array(result)
result2 = torch.from_numpy(result1)
image_var = torch.tensor(images).cuda(async=True)
target = torch.tensor(result2).cuda(async=True)
# compute y_pred
with torch.no_grad():
y_pred = model(image_var)
loss = criterion(y_pred, target)
# measure accuracy and record loss
prec, PRED_COUNT = accuracy(y_pred.data, result2, topk=(1, 1))
losses.update(loss.item(), images.size(0))
acc.update(prec, PRED_COUNT)
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % print_freq == 0:
print('Val: [{0}/{1}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Accuray {acc.val:.3f} ({acc.avg:.3f})'.format(
i, len(val_loader), batch_time=batch_time, loss=losses, acc=acc))
print(' * Accuray {acc.avg:.3f}'.format(acc=acc), '(Previous Best Acc: %.3f)' % best_precision,
' * Loss {loss.avg:.3f}'.format(loss=losses), 'Previous Lowest Loss: %.3f)' % lowest_loss)
# with open('./result/%s.txt' % file_name, 'a') as file:
# file.write('VAIL:Precision: %.8f, Loss: %.8f\n' % (acc.avg, losses.avg))
return acc.avg, losses.avg
# 测试函数
def test(test_loader, model, criterion):
batch_time = AverageMeter()
losses = AverageMeter()
acc = AverageMeter()
end = time.time()
for i, (images, target) in enumerate(test_loader):
result = []
for temp in target:
temp1 = temp.replace("'", "")
temp2 = temp1.replace(",", "")
temp3 = temp2.replace(" ", "")
temp3 = [int(m) for m in temp3]
for j in range(len(temp3)):
if temp3[j] == 1:
l = j
result.append(l)
result1 = np.array(result)
result2 = torch.from_numpy(result1)
image_var = torch.tensor(images).cuda(async=True)
target = torch.tensor(result2).cuda(async=True)
# compute y_pred
with torch.no_grad():
y_pred = model(image_var)
loss = criterion(y_pred, target)
# measure accuracy and record loss
prec, PRED_COUNT = accuracy(y_pred.data, result2, topk=(1, 1))
losses.update(loss.item(), images.size(0))
acc.update(prec, PRED_COUNT)
batch_time.update(time.time() - end)
end = time.time()
if i % print_freq == 0:
print('Test: [{0}/{1}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Accuray {acc.val:.3f} ({acc.avg:.3f})'.format(
i, len(test_loader), batch_time=batch_time, loss=losses, acc=acc))
loss_avg = losses.avg
pre_avg = acc.avg
print(' * Accuray {acc.avg:.3f}'.format(acc=acc),
' * Loss {loss.avg:.3f}'.format(loss=losses))
with open('./result/%s.txt' % file_name, 'a') as file:
file.write('TEST:Precision: %.8f, Loss: %.8f\n' % (pre_avg, loss_avg))
# 保存最新模型以及最优模型
def save_checkpoint(state, is_best, is_lowest_loss, filename='./model/%s/checkpoint.pth.tar' % file_name):
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, './model/%s/model_best.pth.tar' % file_name)
if is_lowest_loss:
shutil.copyfile(filename, './model/%s/lowest_loss.pth.tar' % file_name)
# 用于计算精度和时间的变化
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
# 学习率衰减:lr = lr / lr_decay
def adjust_learning_rate():
nonlocal lr
lr = lr / lr_decay
return optim.Adam(model.parameters(), lr, weight_decay=weight_decay, amsgrad=True)
# 计算top K准确率
def accuracy(y_pred, y_actual, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
final_acc = 0
maxk = max(topk)
# for prob_threshold in np.arange(0, 1, 0.01):
PRED_COUNT = y_actual.size(0)
PRED_CORRECT_COUNT = 0
prob, pred = y_pred.topk(maxk, 1, True, True)
# prob = np.where(prob > prob_threshold, prob, 0)
for j in range(pred.size(0)):
if int(y_actual[j]) == int(pred[j]):
PRED_CORRECT_COUNT += 1
if PRED_COUNT == 0:
final_acc = 0
else:
final_acc = PRED_CORRECT_COUNT / PRED_COUNT
return final_acc * 100, PRED_COUNT
# 程序主体
# 设定GPU ID
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
# 小数据集上,batch size不易过大,如出现out of memory,应再调小batch size
batch_size = 64
# 进程数量,最好不要超过电脑最大进程数,尽量能被batch size整除,windows下报错可以改为workers=0
workers = 12
# epoch数量,分stage进行,跑完一个stage后降低学习率进入下一个stage
stage_epochs = [20, 10, 10]
# 初始学习率
lr = 1e-4
# 学习率衰减系数 (new_lr = lr / lr_decay)
lr_decay = 5
# 正则化系数
weight_decay = 1e-4
# 参数初始化
stage = 0
start_epoch = 0
total_epochs = sum(stage_epochs)
best_precision = 0
lowest_loss = 100
# 设定打印频率,即多少step打印一次,用于观察loss和acc的实时变化
# 打印结果中,括号前面为实时loss和acc,括号内部为epoch内平均loss和acc
print_freq = 1
# 验证集比例
val_ratio = 0.12
# 是否只验证,不训练
evaluate = False
# 是否从断点继续跑
resume = False
# 创建inception_v4模型
# model = DInet.net(num_classes=23)
# model = inception_v3.net(num_classes=16)
model = models.inception_v3(pretrained=True)
model.aux_logit = False
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, 16)
# print(model)
# torch.save(model, './model.pkl')
# import pickle
# f = open('dict_word.pkl', 'rb')
# for line in f:
# print(line)
# word = pickle.load(open("./model.pkl", 'rb'), encoding='utf-8')
# train = pickle.load(open("./model.pkl", 'rb'),encoding='iso-8859-1')
# print(train)
# file=open("./model.txt",'r')
# for temp in train:
# file.write(temp)
# model.save("./model.txt")
# model = torch.nn.DataParallel(model).cuda()
model.cuda()
# optionally resume from a checkpoint
if resume:
checkpoint_path = './model/%s/checkpoint.pth.tar' % file_name
if os.path.isfile(checkpoint_path):
print("=> loading checkpoint '{}'".format(checkpoint_path))
checkpoint = torch.load(checkpoint_path)
start_epoch = checkpoint['epoch'] + 1
best_precision = checkpoint['best_precision']
lowest_loss = checkpoint['lowest_loss']
stage = checkpoint['stage']
lr = checkpoint['lr']
model.load_state_dict(checkpoint['state_dict'])
# 如果中断点恰好为转换stage的点,需要特殊处理
if start_epoch in np.cumsum(stage_epochs)[:-1]:
stage += 1
optimizer = adjust_learning_rate()
model.load_state_dict(torch.load('./model/%s/model_best.pth.tar' % file_name)['state_dict'])
print("=> loaded checkpoint (epoch {})".format(checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(resume))
# 读取训练图片列表
all_data = pd.read_csv('/home/lab326/songpeng/train_val/train.csv')
# 分离训练集和测试集,stratify参数用于分层抽样
train_data_list, val_data_list = train_test_split(all_data, test_size=0.1, stratify=all_data['labels'])
test_data_list = pd.read_csv('/home/lab326/songpeng/train_val/val.csv')
# 读取测试图片列表
# test_data_list = pd.read_csv('data/test.csv')
# 图片归一化,由于采用ImageNet预训练网络,因此这里直接采用ImageNet网络的参数
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# 训练集图片变换,输入网络的尺寸为384*384
train_data = TrainDataset(train_data_list,
transform=transforms.Compose([
transforms.Resize((299, 299)),
# transforms.ColorJitter(0.15, 0.15, 0.15, 0.075),
# transforms.RandomHorizontalFlip(),
# transforms.RandomGrayscale(),
# # transforms.RandomRotation(20),
# FixedRotation([0, 90, 180, 270]),
# transforms.RandomCrop(224),
transforms.ToTensor(),
normalize,
]))
# 验证集图片变换
val_data = ValDataset(val_data_list,
transform=transforms.Compose([
transforms.Resize((299, 299)),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(20),
# transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]))
# 测试集图片变换
test_data = TestDataset(test_data_list,
transform=transforms.Compose([
transforms.Resize((299, 299)),
# transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(20),
# transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]))
# 生成图片迭代器
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, pin_memory=True, num_workers=workers)
val_loader = DataLoader(val_data, batch_size=batch_size * 2, shuffle=False, pin_memory=False, num_workers=workers)
test_loader = DataLoader(test_data, batch_size=batch_size * 2, shuffle=False, pin_memory=False, num_workers=workers)
# 使用交叉熵损失函数
criterion = nn.CrossEntropyLoss().cuda()
# 优化器,使用带amsgrad的Adam
optimizer = optim.Adam(model.parameters(), lr, weight_decay=weight_decay, amsgrad=True)
Loss_list = []
Accuracy_list = []
if evaluate:
validate(val_loader, model, criterion)
else:
# 开始训练
for epoch in range(start_epoch, total_epochs):
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch)
# evaluate on validation set
precision, avg_loss = validate(val_loader, model, criterion)
# precision, avg_loss = validate(val_loader, model, criterion)
Loss_list.append(avg_loss)
precision = precision / 100
Accuracy_list.append(precision)
# 在日志文件中记录每个epoch的精度和loss
with open('./result/%s.txt' % file_name, 'a') as acc_file:
acc_file.write('Epoch: %2d, Precision: %.8f, Loss: %.8f\n' % (epoch, precision, avg_loss))
# 记录最高精度与最低loss,保存最新模型与最佳模型
is_best = precision > best_precision
is_lowest_loss = avg_loss < lowest_loss
best_precision = max(precision, best_precision)
lowest_loss = min(avg_loss, lowest_loss)
state = {
'epoch': epoch,
'state_dict': model.state_dict(),
'best_precision': best_precision,
'lowest_loss': lowest_loss,
'stage': stage,
'lr': lr,
}
save_checkpoint(state, is_best, is_lowest_loss)
# 判断是否进行下一个stage
if (epoch + 1) in np.cumsum(stage_epochs)[:-1]:
stage += 1
lr = lr / lr_decay
# optim.Adam(model.parameters(), lr, weight_decay=weight_decay, amsgrad=True)
optimizer = adjust_learning_rate()
model.load_state_dict(torch.load('./model/%s/model_best.pth.tar' % file_name)['state_dict'])
print('Step into next stage')
with open('./result/%s.txt' % file_name, 'a') as acc_file:
acc_file.write('---------------Step into next stage----------------\n')
# 记录线下最佳分数
with open('./result/%s.txt' % file_name, 'a') as acc_file:
acc_file.write('* best acc: %.8f %s\n' % (best_precision, os.path.basename(__file__)))
with open('./result/best_acc.txt', 'a') as acc_file:
acc_file.write('%s * best acc: %.8f %s\n' % (
time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())), best_precision,
os.path.basename(__file__)))
# 读取最佳模型,预测测试集
best_model = torch.load('./model/%s/lowest_loss.pth.tar' % file_name)
model.load_state_dict(best_model['state_dict'])
test(test_loader, model, criterion)
# 释放GPU缓存
torch.cuda.empty_cache()
return Loss_list, Accuracy_list