Hi !
I’m training a model for facial keypoints detection, using the Helen dataset.
I’m using a Imagenet pretrained mobilenetV2 as backbone, retraining only the final layers for 10 epochs on the full dataset.
I’m getting very poor results and I wanted to know whether someone could help me out. Basically, the model sticks all the points in the center and after the first epoch both the training and validation losses stop decreasing.
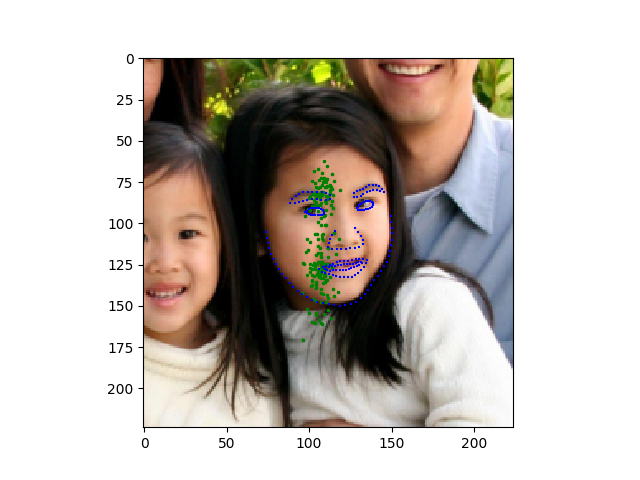
I’m not doing particularly fancy things and I don’t see what prevents training.
First, for the model, :
backbone = models.mobilenet_v2(pretrained = False)
backbone.load_state_dict(torch.load('./mb_net.pth'))
features = backbone.features
predictions = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(1, 1)),
Flatten(),
nn.Linear(1280, 1000),
nn.Tanh(),
nn.Linear(1000, 1000),
nn.Tanh(),
nn.Linear(1000,512),
nn.ReLU(inplace = True),
nn.Linear(512,
for p in features.parameters():
p.requires_grad = False
self.predictor = nn.Sequential(features, predictions)
Then, for training, I do:
predictor = FaceModel()
loss_fn = nn.MSELoss(size_average = False)
adam = optim.Adam([p for p in predictor.parameters() if p.requires_grad], lr = 3e-4)
for epoch in range(epochs):
predictor = predictor.to(device)
predictor.train()
train_loss = 0.
for i, sample in enumerate(train_loader):
x = sample['image']
y = sample['points']
preds = predictor(x.to(device))
loss = loss_fn(preds, y.to(device))
adam.zero_grad()
loss.backward()
adam.step()
# keep track of metrics,
# validation loop...
Concerning data augmentation, I’m first rescaling the images to be 224*224, then I ensure they are float values, comprised between 0 and 1 and I also make sure the keypoints values lie between 0 and 1. I apply horizontal flipping with p = 0.5 and that’s it. Should I use Imagenet stats to normalize image channels ?
Other than that, I really don’t see an obvious error. Could maybe someone point me in the right direction ?
Thanks a lot !