Hi everyone,
Let’s assume we have a tensor h_i over dimension F, a weight matrix W of dimension FxF and a function a from FxF → 1. I represented a as a vector of 2Fx1.
I would like to compute 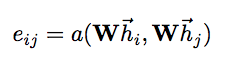 .
.
Currently, I’m doing
class MyModule(nn.Module):
def __init__(self, in_features, out_features):
super(MyModule, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.W = nn.Parameter(nn.init.xavier_uniform(torch.Tensor(in_features, out_features).type(torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor), gain=np.sqrt(2.0)), requires_grad=True)
self.a = nn.Parameter(nn.init.xavier_uniform(torch.Tensor(2*out_features, 1).type(torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor), gain=np.sqrt(2.0)), requires_grad=True)
def forward(self, input):
h = torch.mm(input, self.W)
N = h.size()[0]
a_input = torch.cat([h.repeat(1, N).view(N * N, -1), h.repeat(N, 1)], dim=1).view(N, -1, 2 * self.out_features)
e = F.elu(torch.matmul(a_input, self.a).squeeze(2))
return e
This is working, but as you can imagine it takes ~7GB of memory on my GPU. If I would like to run multiple instances in my GPU, I can’t due to the memory usage.
Would you see a way to do this operation more efficiently ? I really think that using repeat “waste” a lot of memory. Maybe there is a clever way to handle this ?
Thank you for your answers !