Hi, I’m currently working on encoder-decoder transformer model pre-training and trying to train it with apex’s distributed dataparallel settings.
As I know, it executes multi-processing and each process is assigned to one GPU.
And as I searched, this distributed training certainly has an advantage that it reduces memory imbalance problem than other methods do.
But in my training, GPU’s memory allocations are different and also GPU-utils are so low, which indicates that each GPU does not work fully.
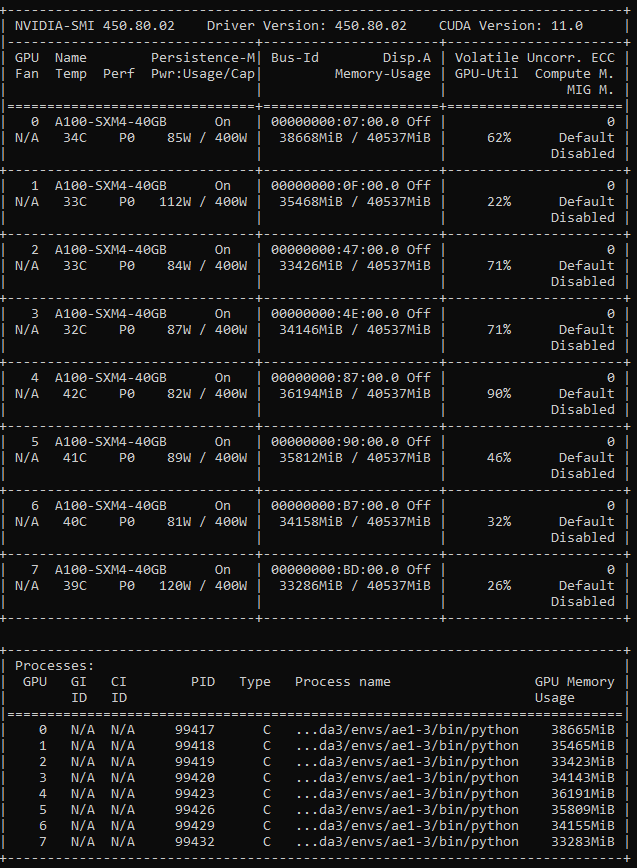
- Is there any reason why each GPU’s memory is used differently? Is there I misunderstood?
- Why is GPU’s utilization so low? Is there anything I missed?
- One more thing, before I tried with full data, I tested the smaller set with same batch sizes. In that setting, the training was completed with no problems. But with full data, I had to decrease the batch size quite a lot since it raised CUDA out-of-memory error. I don’t know why this happened because I think at least the size of one batch put into each GPU is same in each iteration.
Here is the training code only with essential parts.
import torch.distributed as dist
from apex.parallel import DistributedDataParallel as DDP
from apex import amp
from torch.utils.data.distributed import DistributedSampler
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark = True
torch.cuda.set_device(args.local_rank)
device = torch.device(f'cuda:{args.local_rank}')
dist.init_process_group(backend='nccl', init_method='env://', rank=args.local_rank, world_size=args.nproc_per_node)
data = PretrainDataset(path, data)
ppd = PretrainPadCollate(pad_id)
sampler = DistributedSampler(data)
data_loader = DataLoader(
data,
collate_fn=ppd.pad_collate,
batch_size=args.batch,
shuffle=True if sampler is None else False,
pin_memory=True,
num_workers=4,
sampler=sampler
)
model = ModelClass().to(device)
opt = Adafactor(model.parameters(), lr=args.lr, relative_step=False)
scheduler = lr_scheduler.ExponentialLR(opt, gamma=1/math.sqrt(args.warmup_steps))
model, opt = amp.initialize(model, opt, opt_level='O1')
model = DDP(model, delay_allreduce=True)
# Train iterations
train_step = 1
for batch in data_loader:
opt.zero_grad()
outputs = model(batch)
loss = outputs[0]
with amp.scale_loss(loss, opt) as scaled_loss:
scaled_loss.backward()
opt.step()
if train_step > args.warmup_steps:
scheduler.gamma = 1/math.sqrt(train_step)
scheduler.step()
Thank you.