When trying to change this line to something like:
temp_loader = DataLoader(held_out_data,batch_size = 100)
held_out_features = torch.empty(0, dtype = torch.float, device=device)
for _,data in enumerate(temp_loader):
held_out_features = torch.cat((held_out_features, model(data)[1]),0)
I’ve also tried:
held_out_features = torch.empty(0, dtype = torch.float, device=device, requires_grad=True)
for j in range(0,len(held_out_data),100):
data = held_out_data[j:j+100,:,:,:]
_,temp,_ = model(data)
held_out_features = torch.cat((held_out_features, temp),0)
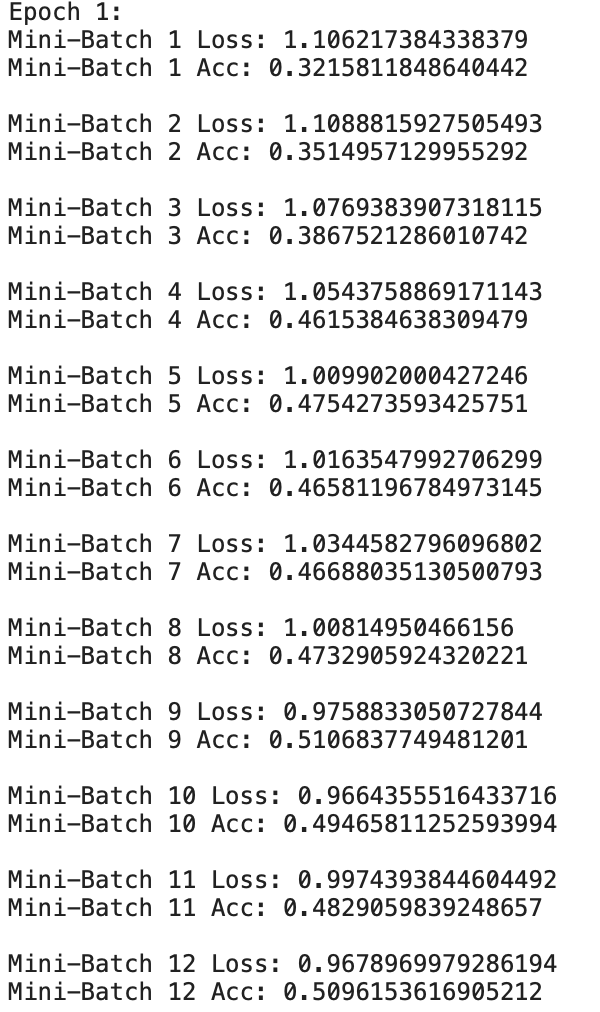
Both of these relieve the memory issue, but then the loss doesn’t decrease steadily (or at all) as before - it hovers around 1.1 throughout mini batches/epochs (I’d post another image but since I’m a new user I can’t).
I don’t know how exactly the first code looks like, but the two suggested workarounds would accumulate the computation graphs for the entire dataset and I would assume you would be running out of memory (assuming the first approach trains on each batch).
Could you describe the issue in more detail and explain how the first approach is written?
The code above appears in a train function. held_out_data is the tensor we would like to feed into model. It contains roughly 900 images. For the purposes of the the project I’m working on, it’s important that we process all of them each training iteration. We make predictions on held_out_data and that’s how we generate loss. When trying the first approach, we see the loss decreasing, but the runtime is very slow and occasionally runs out of memory. When we switch to the 2nd/3rd approach, it doesn’t run out of memory (because we process in groups of 100 instead of all 900 at once), but the loss doesn’t decrease, even though held_out_features should be the same in either case. Let me know if you need further clarification.