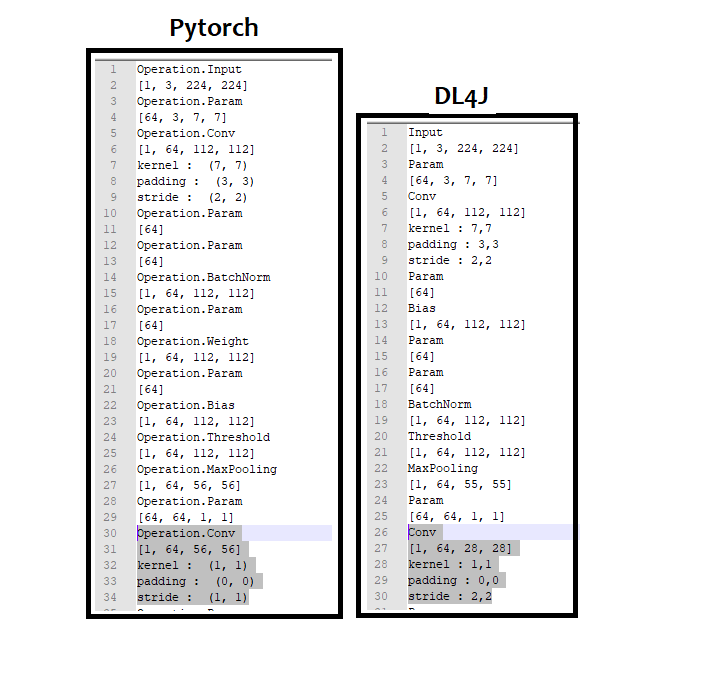
Hi, I am comparing few zoo models implementation in DL4J with Pytorch zoo models and found
that the padding in Convolution layers does not match most of time ?
For Resnet50 and SqueezeNet :
In DL4J, they do not apply padding : [0, 0] ; while in PyTorch they have padding [1, 1].
This results in different output in layers
In DL4J, they apply Bias in Conv layers while in PyTorch, they do not.
Why such irregularities in Network structure across frameworks ?
I guess PyTorch might have used the original Caffe implementation as the base?
As you can see in the prototxt, the conv layers do not use the bias, as it would be cancelled by the following batchnorm layers.
- the stride mismatch in second convolution operation (Torch uses 1 while **dl4j uses 2! ) . This results in decreasing the output volume rapidly in dl4j.