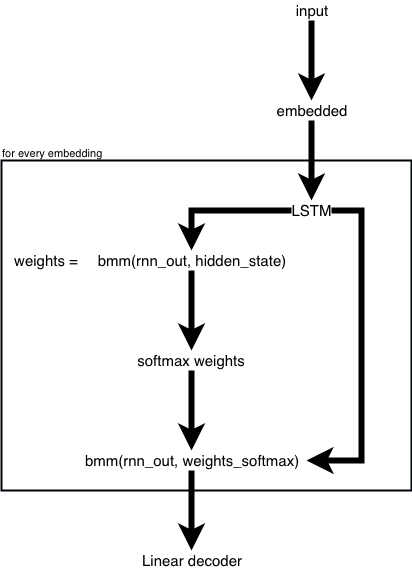
I am trying to implement attention mechanism. Unfortunately, my current implementation has high loss than the model without attention.
Any ideas on how to improve the model or whether it even makes sense at the moment…
I am trying to implement attention mechanism. Unfortunately, my current implementation has high loss than the model without attention.
Any ideas on how to improve the model or whether it even makes sense at the moment…
Why are you multiplying the hidden states and the output of the lstm? What do you mean by a linear decoder? Could you site the source of this architecture? The standard attention mechanism does not look like this.