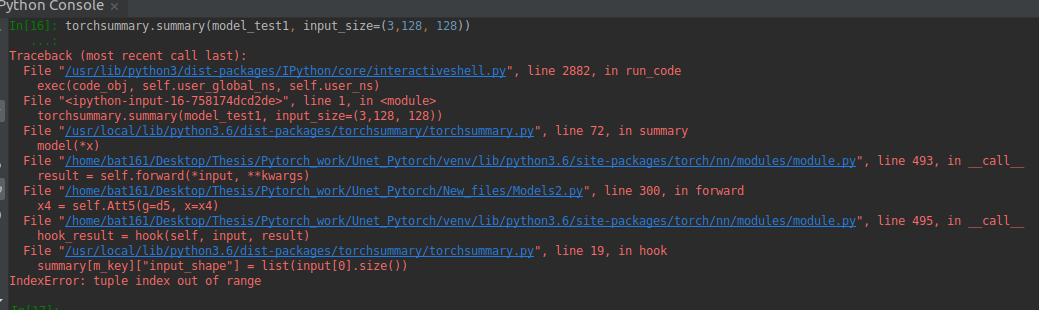
Sorry for the trouble.
Took me sometime to get used to this.
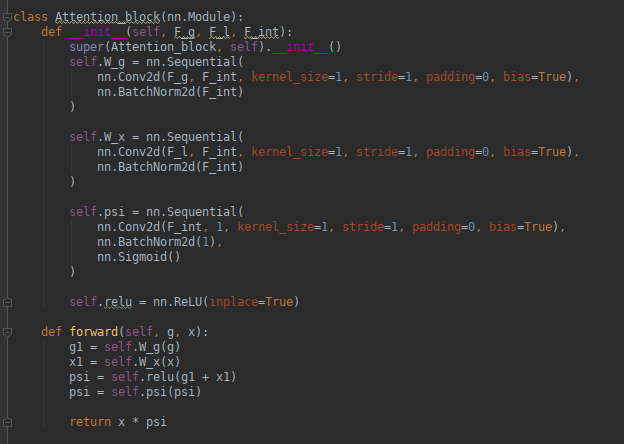
This is my attention Block:
class Attention_block(nn.Module):
def __init__(self, F_g, F_l, F_int):
super(Attention_block, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self, g, x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1 + x1)
psi = self.psi(psi)
return x * psi
This is my model:
class AttU_Net(nn.Module):
def __init__(self, img_ch=3, output_ch=1):
super(AttU_Net, self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv1 = conv_block(ch_in=img_ch, ch_out=64)
self.Conv2 = conv_block(ch_in=64, ch_out=128)
self.Conv3 = conv_block(ch_in=128, ch_out=256)
self.Conv4 = conv_block(ch_in=256, ch_out=512)
self.Conv5 = conv_block(ch_in=512, ch_out=1024)
self.Up5 = up_conv(ch_in=1024, ch_out=512)
self.Att5 = Attention_block(F_g=512, F_l=512, F_int=256)
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512, ch_out=256)
self.Att4 = Attention_block(F_g=256, F_l=256, F_int=128)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256, ch_out=128)
self.Att3 = Attention_block(F_g=128, F_l=128, F_int=64)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128, ch_out=64)
self.Att2 = Attention_block(F_g=64, F_l=64, F_int=32)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2d(64, output_ch, kernel_size=1, stride=1, padding=0)
self.active = torch.nn.Sigmoid()
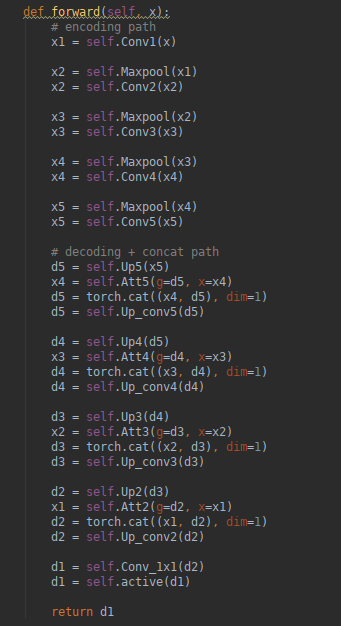
def forward(self, x):
# encoding path
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# decoding + concat path
d5 = self.Up5(x5)
x4 = self.Att5(g=d5, x=x4)
d5 = torch.cat((x4, d5), dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4, x=x3)
d4 = torch.cat((x3, d4), dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3, x=x2)
d3 = torch.cat((x2, d3), dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2, x=x1)
d2 = torch.cat((x1, d2), dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
d1 = self.active(d1)
return d1
This is what I am passing:
model_test1 = AttU_Net(3, 1).to(device)
torchsummary.summary(model_test1, input_size=(3, 128, 128))