Hi,
I’m trying to implement a vanilla autoencoder for the STL10 image dataset, but
I’m facing some issues.
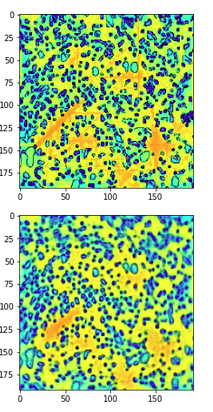
The output of the model looks rather blurry and doesn’t really capture much of the original image. Could be due to bad model size (approx 3M parameters) or poor architecture. What I do not understand is the ‘blockiness’ of the output (attached figure) - it looks like the output image consists of 9 square segments with visible borders, and it happens for every output image. Any ideas where such behaviour coming from?
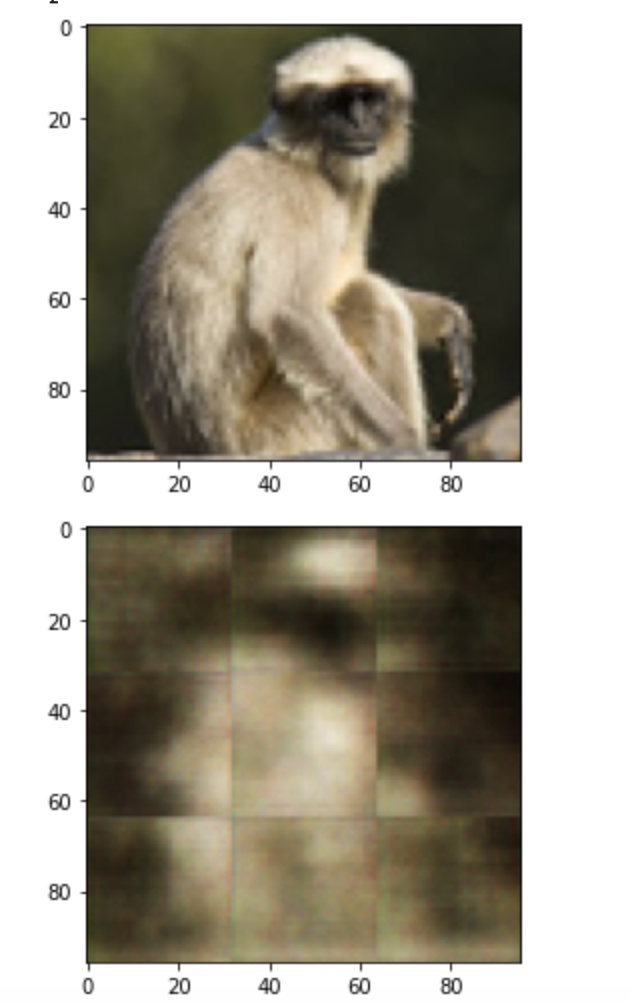
I’m using BCELoss, Adam optimizer, 128 batch size and the model architecture looks like
self.downscale_conv = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=5, stride=2, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=5, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=5, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 64, kernel_size=5, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(),
)
self.linearEnc = nn.Sequential(
nn.Linear(1024, 900),
nn.LeakyReLU(),
)
self.linearDec = nn.Sequential(
nn.Linear(900, 1024),
nn.LeakyReLU(),
)
self.upscale_conv = nn.Sequential(
nn.ConvTranspose2d(64,128, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.ConvTranspose2d(128,128, kernel_size=3, stride=2, padding=0),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.ConvTranspose2d(128, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(),
nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(),
nn.ConvTranspose2d(64, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(),
nn.Conv2d(64, 3, kernel_size=6, stride=1, padding=2),
nn.Sigmoid(),
)