Hello!, I have a question about pytorch autograd engine.
I’m searching the efficiency of torch matrix multiplication and autograd API.
**The first question is **
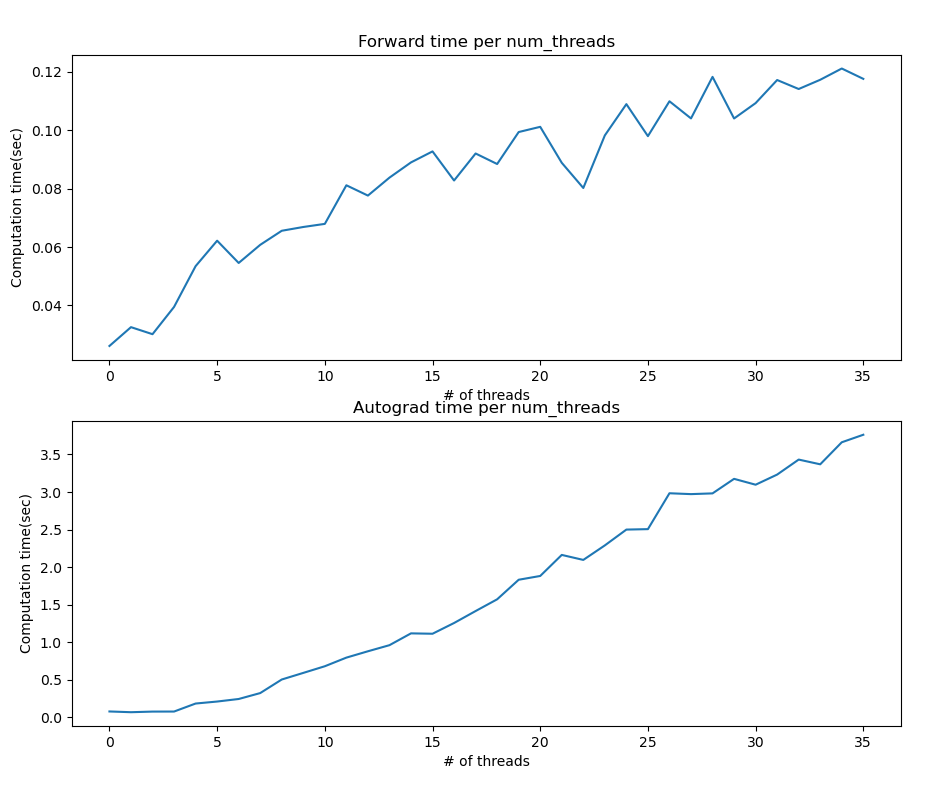
“Is there special relationship between the number of CPU thread and autograd API?”
- In my case, I created 64nodes-2hidden_layers F.C model. Using the model, I changed
the number of CPU threads(from 1 to 36). As I know, the more user use CPU threads,
the more computation time reduces. However, my test code shows totally different results.
It is also strange that using small size of F.C model does not affect computation time in different number of CPU threads.
The second question is
**“What is the minimum F.C model matrix size that GPU device shows better computational time efficiency compared to CPU device?”"
- In the same model that I mentioned above, GPU device shows inferior performance compared to CPU device, regarding computaion time. If inferior performance due to the small size of N.N model, then will it be useful using CPU than GPU purely in perspective of computational time?
Forward propagation ratio GPU/CPU : 1.412X
Autograd propagation ration GPU/CPU: 1.13X
Here is my code.
import torch
import time
import matplotlib.pyplot as plt
from datetime import timedelta
device1 = torch.device('cpu')
device2 = torch.device('cuda')
maximum_threads = torch.get_num_threads()
forward_time_per_threads, autograd_time_per_threads = [], []
for i in range(1,maximum_threads+1):
torch.set_num_threads(int(i))
forward_buffer, autograd_buffer = 0,0
x = torch.randn((128,3))
x.requires_grad=True
w1 = torch.randn(3,64)
w2 = torch.randn(64,64)
w3 = torch.randn(64,1)
for _ in range(1000):
start = time.time()
y = x @ w1 @ w2 @ w3
forward_time = time.time()-start
forward_buffer += forward_time
start = time.time()
dydx = torch.autograd.grad(y.sum(),x,create_graph=True)[0]
autograd_time = time.time()-start
autograd_buffer += autograd_time
forward_time_per_threads.append(forward_buffer)
autograd_time_per_threads.append(autograd_buffer)
fig = plt.figure(figsize=(15,10))
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
ax1.plot(forward_time_per_threads)
ax2.plot(autograd_time_per_threads)
ax1.set(xlabel='# of threads',ylabel='Computation time(sec)')
ax2.set(xlabel='# of threads',ylabel='Computation time(sec)')
ax1.set_title('Forward time per num_threads')
ax2.set_title('Autograd time per num_threads')
plt.show()
cpu_forward_buffer, cpu_autograd_buffer = 0,0
x = torch.randn((128,3)).to(device1)
x.requires_grad=True
w1 = torch.randn(3,64).to(device1)
w2 = torch.randn(64,64).to(device1)
w3 = torch.randn(64,1).to(device1)
for _ in range(1000):
start = time.time()
y = x @ w1 @ w2 @ w3
forward_time = time.time()-start
cpu_forward_buffer += forward_time
start = time.time()
dydx = torch.autograd.grad(y.sum(),x,create_graph=True)[0]
autograd_time = time.time()-start
cpu_autograd_buffer += autograd_time
gpu_forward_buffer, gpu_autograd_buffer = 0,0
x = torch.randn((128,3)).to(device2)
x.requires_grad=True
w1 = torch.randn(3,64).to(device2)
w2 = torch.randn(64,64).to(device2)
w3 = torch.randn(64,1).to(device2)
for _ in range(1000):
start = time.time()
y = x @ w1 @ w2 @ w3
forward_time = time.time()-start
gpu_forward_buffer += forward_time
start = time.time()
dydx = torch.autograd.grad(y.sum(),x,create_graph=True)[0]
autograd_time = time.time()-start
gpu_autograd_buffer += autograd_time
print(f'Forward propagation time ratio(gpu/cpu) : {gpu_forward_buffer/cpu_forward_buffer}X')
print(f'Autograd time ratio(gpu/cpu) : {gpu_autograd_buffer/cpu_autograd_buffer}X')
Thank you