i am using pytorch, and i need to calculate the gradients of the network at a series of points to add to the loss.
i used the code in the function get_sdf_gradient_dont_work:
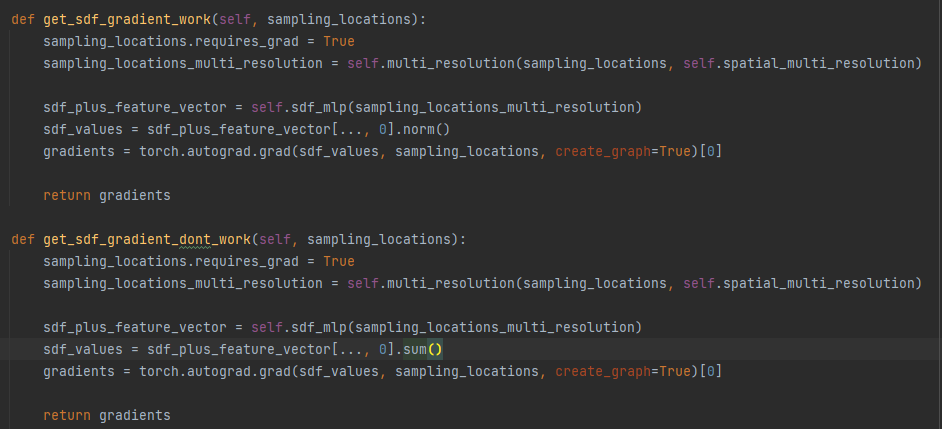
and i got a memory leak in the GPU.
but when i use the code in the function get_sdf_gradient_work, it seems to work (not the functionality i needed, but no memory leak)
the network is a simple MLP using only linear layers and LeakyReLU.
and the multiresolution function is:
@staticmethod
def multi_resolution(points, resolutions):
resolutions_sin = torch.cat([torch.sin((2 ** i) * pi * points) for i in range(1, resolutions)], dim=-1)
resolutions_cos = torch.cat([torch.cos((2 ** i) * pi * points) for i in range(1, resolutions)], dim=-1)
return torch.cat([points, resolutions_sin, resolutions_cos], dim=-1)
does someone knows how to solve this ?