I’m fiddling around with a loss function that measures similarity between feature maps in pixel space. The target is a sparse map of 0s or 1s of size 224x224. The key aspect of what I’m trying is that I only want the value of local maxima of the prediction to be back propagated, meaning that I need to mask the predicted map.
Within the loss I do this:
def forward(self, inputs, targets):
pooled = self.max_pool(inputs)
mask = (inputs == pooled).float()
maxima = inputs * mask
return self.bce_loss(maxima, targets)
By using max pooling and comparing it to the initial mask, I create a mask that only highlights local maxima. Multiplying this to the initial values gets my wanted logits back.
What I want is to back propagate only those information that were part of the mask (have a 1.0) and not those values that are set to 0.0.
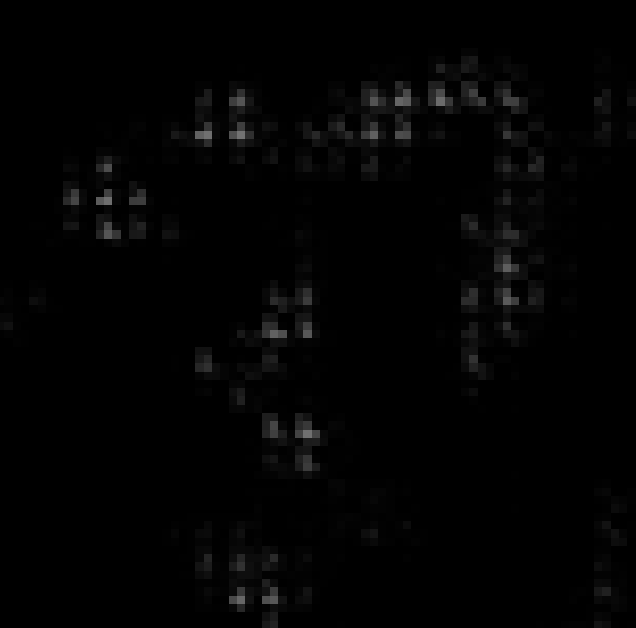
My direct model outputs show a very strong checkerboard pattern, which is why I suspect also the masked out values are somehow being back propagated. I expected the output to look a lot more smooth. E.g. I expected the values around local maxima to be closer to the maxima instead of being zero (on the grid lines).
I do use transposed convs with k=2 for upsampling.
Where am I going wrong? Is there a fundamental problem in my approach?