So I have this network that has the following architecture:
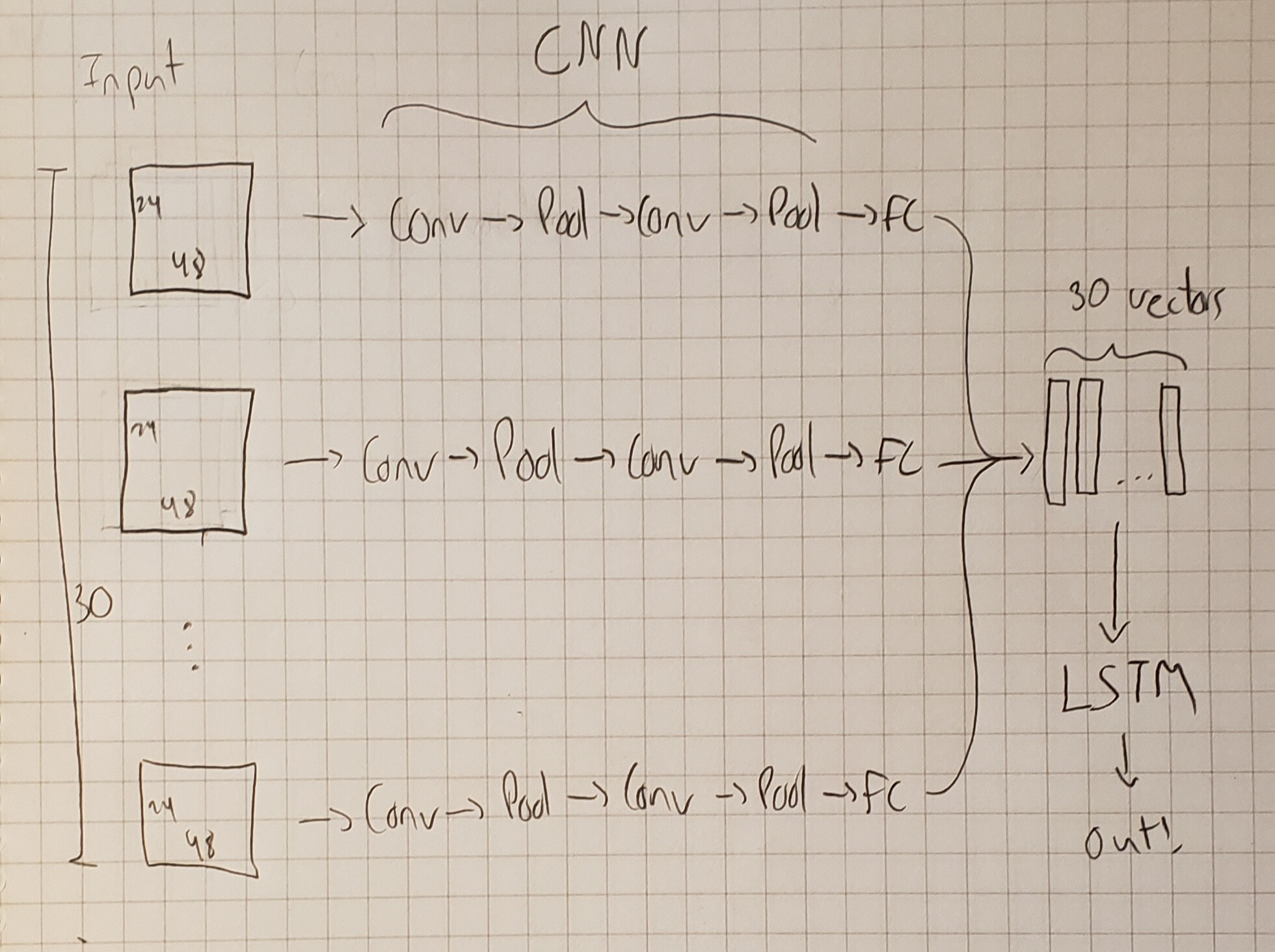
The goal of this architecture is to extract features out of a sequence of 30 frames, without knowing what those features are. The 30 frames are represented as images, but they aren’t real images, which is why we can’t have a classification prior to passing it through the CNN.
After the “images” go through the CNN, they become vectors, which are fed to an LSTM who will try to find patterns through time. We have the label that should be output by the LSTM, a 0 or a 1, but we don’t have the classification for the CNN. This architecture’s whole goal is to get rid of feature engineering, basically (based on this paper: https://www.researchgate.net/publication/319897145_Deep_Model_for_Dropout_Prediction_in_MOOCs).
Now, my question is whether or not our model would backpropagate properly. Here is our code:
class MyCNN(nn.Module):
def __init__(self):
super(MyCNN, self).__init__()
# convolutional layer (sees matrices 24x48x1)
self.conv1 = nn.Conv2d(1, 20, 5)
# convolutional layer (sees matrices 20x44x20)
self.conv2 = nn.Conv2d(20, 50, 5)
# max pooling layer
self.pool = nn.MaxPool2d(2, 2)
# fully conntected layer (takes in input a matric of 3x9x50, makes it into a vector of 20)
self.fc = nn.Linear(3 * 9 * 50, 20)
def forward(self, x):
# add sequence of convolutional and max pooling layers
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
# flatten image input (is it to keep???)
x = x.view(-1, 3 * 9 * 50)
# add 1st hidden layer, with relu activation function
x = F.relu(self.fc(x))
return x
We then define the ConRec network, who takes as input the output of MyCNN():
class ConRec(nn.Module):
def __init__(self):
super(ConRec, self).__init__()
# lstm layer (20 long vectors)
self.lstm = nn.LSTM(20, 50, 1, batch_first=True)
def forward(self, x):
x = F.relu(self.lstm(x))
return x
And finally, we gather the output of the 30 frames passed through the CNN and concatenate them (the code might be wrong, I’m still a beginner!). The CNN is the same for all 30 branches, so it only has one set of weights.
And then we feed that through the LSTM.
for d in data:
output=MyCNN(d)
full_out=torch.cat([full_out, output], dim=1)
#30 items in data
result=ConRec(full_out)
When I apply the loss, would it backpropagate properly? I’m afraid it would only apply the loss to the LSTM and not the CNN, since they’re not directly connected.