@albanD @ptrblck Any ideas? I am stuck.
One thing that I realise is missing from the code snippet I have shared is that there’s no provision for storage of gradients of the form: 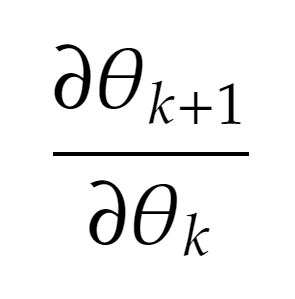 owing to the fact that
owing to the fact that nn.Parameters are leaf Tensors because of which any operations on them won’t be traced in the computation graph.
For that, I think I will have to employ the hack needed for meta-learning wherein we need these kinds of derivatives. But even with that, I still haven’t been able to answer my question completely.