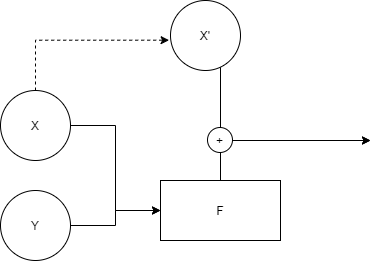
Here X (last hidden state) and Y (all hidden states) are outputs of LSTM, F is attention computation and X’ is a copy of X, + is elementwise summation. My question is, how should I backprop in this case? Should I detach the output of F (context vector) before summation with X’? Also, is it better to clone() X or just create a new variable?
Why I’m concerned something’s not right is because for all inputs the softmax distribution is always the same: all 0s and the last one (dot-product of the last hidden state with itself) is 1.