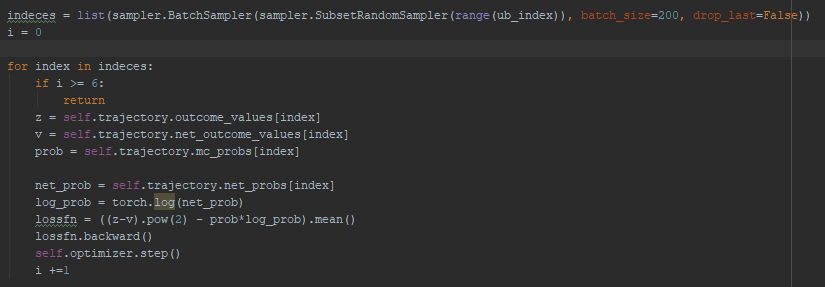
Hello. I am not sure why my code produces the error. I dont think that I should use the retain_graph=True feature but I am not sure how else to fix my problem.
It works good the first time but for some reason it tries to go to the old graph even though I calculate all tensors from the loss function new. I would assume that the problem is because of the Trajectory object (net_outcome_values and net_probs have required_grad=True), but I am not sure how to fix it. Any help is greatly appreciated!
Error: RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
It is pytorch fault for this. When you call .backward() pytorch deleted all the intermediate results, so as to preserve memory, which also results in the deletion of the computation graph. In your example you first created your computation graph, then you called lossfn.backward(), after that you don’t have the graph and so not gradients can flow.
To avoid this situation you should use retain_graph=True at the last step i.e. lossfn.backward(retain_graph=True), just remember to zero your gradients before that.
Hey, so the problem is that I only take a part of the net_outcome_values. So when I want to take another batch of that tensor pytorch already backpropagated through that and the error is thrown. I solved the problem by calculating each v and the net_probs directly there and dont save them earlier in my program.
Still, the question remains: If I have a problem where I need to save the network outputs earlier and want to sample them in batches, is my only option to use retain_graph=True ? Is there even such a use case?
I tried retain_graph=True but the time stacked up so fast to a point where it was not possible to use this method.
Thanks for your answer though, really appreciate it!