Hello,
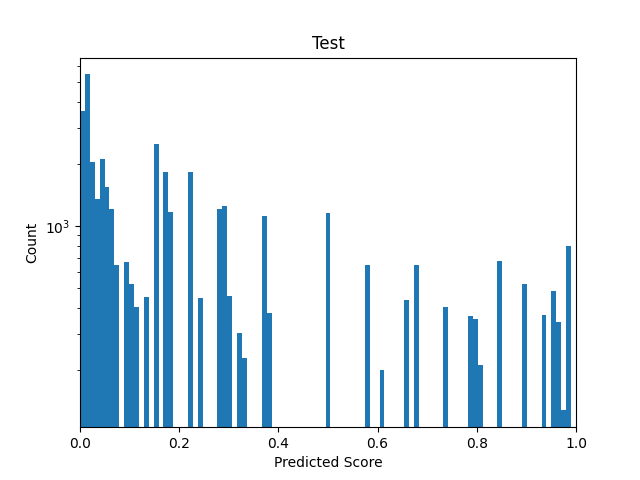
I want to train a student network and therefore collected all the probability outputs of my teacher (~ 41.000) to create my dataset for the student. The distribution (Binned in 100 bins) looks like this (I already ploted the weights for the WeightedRandomSampler as curve):
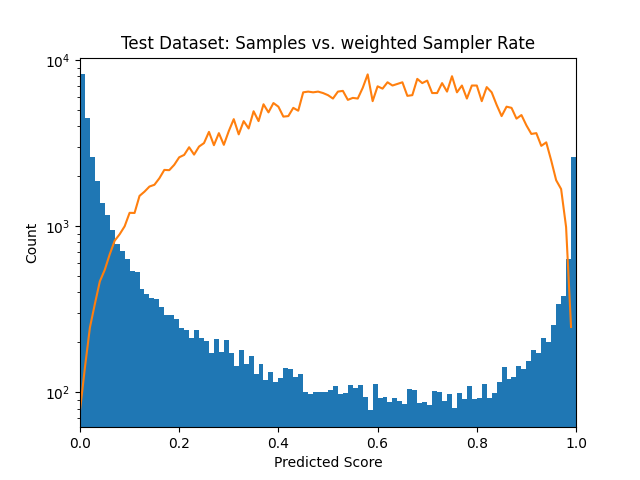
The weights are obtained by:
batch_size = 100
weights = 1. / dataset.targets.bincount().double()
sampler = torch.utils.data.sampler.WeightedRandomSampler(weights=weights, num_samples=len(dataset), replacement=True)
kwargs = {'num_workers': 1, 'pin_memory': True} if device == 'cuda' else {}
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, sampler=sampler, **kwargs)
After running through the whole dataloader I receive the following distribution: See next post
The amount of samples seems okay, but why are there so huge gaps in between? For the amount of samples I expected these to be more filled.
Thank you in advance!