Hello everyone, I am currently facing a problem regarding a small GPU memory during my deep learning project. To handle this, I am currently training in batch size =4 but this requires a significant sampling from the initial data to be able to fit into my GPU. Hence, I think I have to use batch size = 1 which is a stochastic gd. However, I have read some posts saying that batch normalization is not good to be used in batch size =1. If it is true, what should I do with the BN in my model? Do I have to remove them?
The batch statistics might be noise with a single sample or your model might even raise an error, if no statistics can be computed from the input.
However, as usual, it depends on your use case and I would recommend to run some experiments and play around with the momentum term in the batchnorm layers.
@ptrblck Hi than you for your reply!
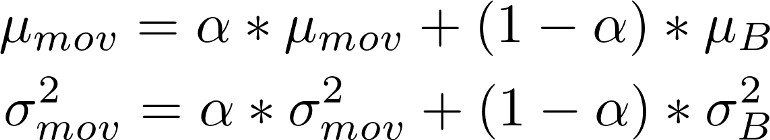
I realized that my momentum value is set in really low value currently, but apparently it is recommended to set high value when I am training in small batch.
Using the equation above, could you please interpret to me how the statement is valid?
Be a bit careful about the momentum definition in batchnorm layers, as they might differ from other definitions.
From the docs:
This momentum argument is different from one used in optimizer classes and the conventional notion of momentum. Mathematically, the update rule for running statistics here is x_hat_new = (1 - momentum) * x_hat + momentum * x_t, where x_hat is the estimated statistic and x_t is the new observed value.
Based on your posted formula (assuming alpha is the momentum) the definition differs as explained in the docs.
@ptrblck, thank you for the reply.
Base on the document, it means that the momentum in pytorch is opposite to the equation I posted. Hence, it should be set really low like 0.1 during training with low batch.
Is this correct?
The default value is already set to 0.1, so you might want to decrease it even further.
Ok thank you for the hlep!!
@ptrblck, hi I just tried changing the momentum for batch norm, but unfortunately it did not work.
The error is triggered during batchnorm1d with batch size 1.
It seems that it is not possible to train in batch size 1 with batchnorm1d.
Is this correct? If so, is there any alternative solution that I can do?
You cannot use batchnorm layers with a single sample, if the temporal dimension also contains only a single time step as seen here:
bn = nn.BatchNorm1d(3)
x = torch.randn(1, 3, 10)
out = bn(x)
x = torch.randn(1, 3, 1)
out = bn(x) # error
since the mean would just be the channel values and the stddev cannot be calculated.
I’m not sure, if any normalization layer would make sense in such a use case, but lets wait for others to chime in.
You can try LayerNorm as a substitute, but it is not always performing as well, being too different from batch norm. Or something like GitHub - Cerebras/online-normalization: Online Normalization for Training Neural Networks (Companion Repository)
@googlebot Thank you for recommending an excellent paper. I will have a read and try it!!
Wouldn’t LayerNorm calculate the stats from the single pixel and thus return a zero output or do I misunderstand the use case?
It is applied to vectors in feature space, though I’ve read that layer norm doesn’t work well with convolutions, stats would be per image region. I think the problem is rather with channel importance equalization, as layer norm “ties” all dimensions; I guess that is bad for early vision filters.
PS: if that’s not clear, I meant group norm applied to a channels last permuted tensor