I’m trying to run a multi label classifier and I have used nn.BCEWithLogitsLoss as my model’s loss. But when I want to use: accuracy_score(output_labels, input_labels) I got this error:
ValueError: Classification metrics can’t handle a mix of binary and multilabel-indicator targets.
What should i do?
I don’t know how your inputs look to this method, but this code snippet works for a multilabel classification:
from sklearn.metrics import accuracy_score
output = torch.tensor([[0., 1., 1., 0.],
[0., 1., 0., 1.]])
target = torch.tensor([[0., 1., 0., 1],
[0., 1., 0. ,1]])
accuracy_score(output, target)
and computes the accuracy as described in the docs:
In multilabel classification, this function computes subset accuracy: the set of labels predicted for a sample must exactly match the corresponding set of labels in y_true.
I am implementing a UNET with a binary mask(0-black background and 1-white mask). I realized the black pixels are more than the white pixels in my training set. So I am planning to update my custom loss function.
class CustomBCELoss:
def __init__(self):
self.bce = nn.BCELoss()
def __call__(self, yhat, ys):
yhat = torch.sigmoid(yhat)
valid = (ys == 1) | (ys == 0)
if bool(valid.any()):
return self.bce(yhat[valid], ys[valid])
else:
return None
return self.bce(yhat, ys)
This is the new loss function where I am using BCELosswithLogits and pos_weight parameter to balance the data.
class CustomBCELossLogits:
def __init__(self):
self.bceLogit = nn.BCEWithLogitsLoss()
def __call__(self, yhat, ys):
valid = (ys == 1) | (ys == 0)
weight = torch.tensor([3,1])
weights = weight.to('cuda')
if bool(valid.any()):
return self.bceLogit(yhat[valid], ys[valid], pos_weight=weights)
else:
return None
return self.bceLogit(yhat, ys, pos_weight=weights)
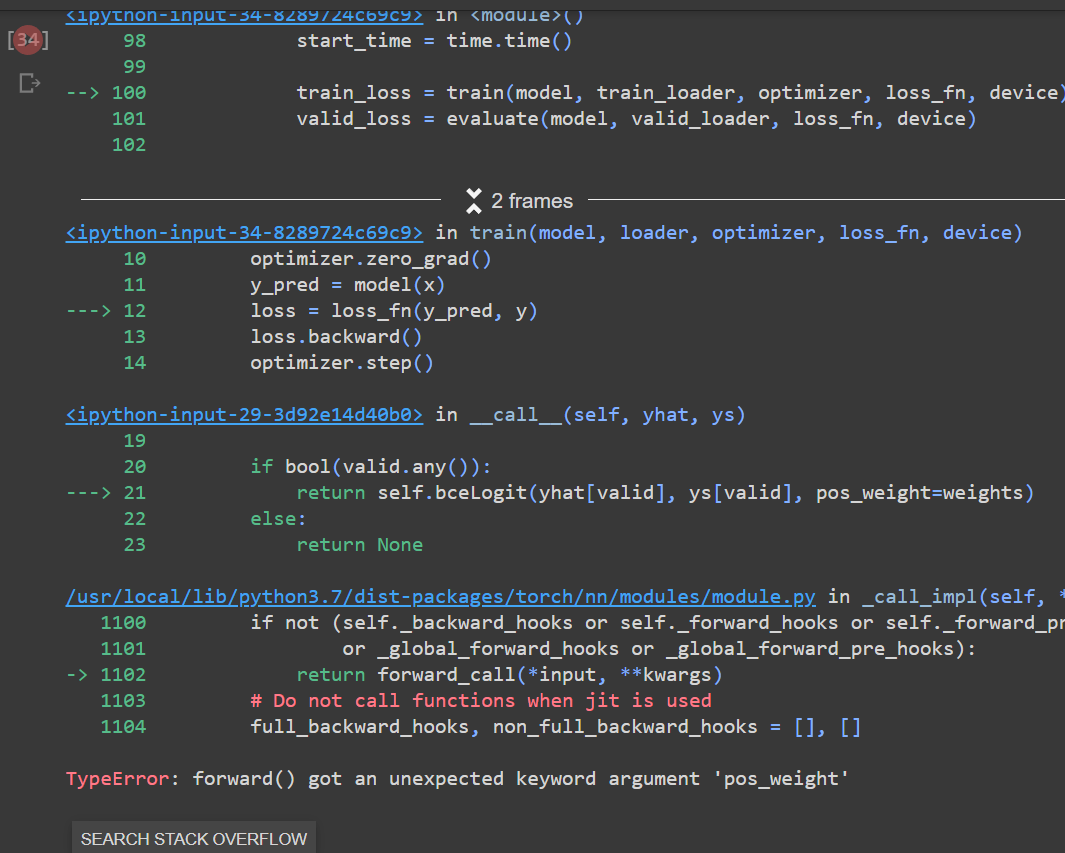
- Is this approach correct?@ptrblck Please suggest.
- I am getting an error with the pos_weights parameter. I have picked the weights as [3,1] → referring to white pixels to be prioritized 3 times.
I don’t know the class frequencies, but refer to the docs to set the pos_weight:
For example, if a dataset contains 100 positive and 300 negative examples of a single class, then pos_weight for the class should be equal to 300/100==3. The loss would act as if the dataset contains 3×100=300 positive examples.
The error is raised since pos_weight should be passed as an argument to the class initialization, not the forward method. If you want to use it in a functional way you could use F.binary_cross_entropy_with_logits instead.
Thank you your input.
@ptrblck Hi, could you please tell me why the threshold was set to 0.0 instead of 0.5 if we go by the range of the Sigmoid Function? Please tell me what I am missing. If 0.0 should be the threshold when applying BCEWithLogitsLoss, should I keep the same threshold in training and testing both parts of my model?
That’s not the case as my post mentioned logits:
To get the predictions from logits, you could apply a threshold (e.g.
out > 0.0) for a binary or multi-label classification use case
If you apply sigmoid on the output you should use a threshold as a probability, such as 0.5.
@KFrank explains this in more detail in this post and shares approaches to transform between logit and probability thresholds.
1 Like
Hi, Can you tell me academically and in plain language what torch.nn.BCEWithLogitsLoss() does?
Can you tell me academically and in plain language what torch.nn.BCEWithLogitsLoss() does?
@ptrblck Hi again, what if I still need probabilities over labels, let’s say to draw an ROC-AUC curve, can I get that using BCEWithLogitsLoss or do I need BCELoss for that?
Neither will return probabilities as these functions calculate the loss. Apply torch.sigmoid on the logits returned by the model outside of the forward method and use it for your stats calculation. Pass the raw logits to nn.BCEWithLogitsLoss.
Apologies, I think I understood that. Can you please check this implementation in my train and test functions now to see if I’m doing it right for BCEWithLogitsLoss()?
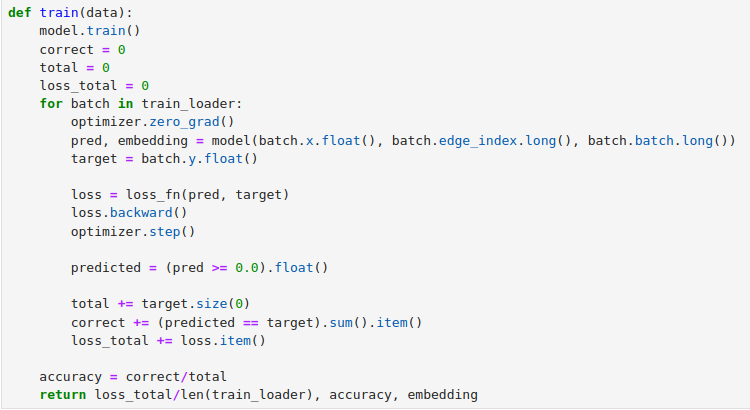
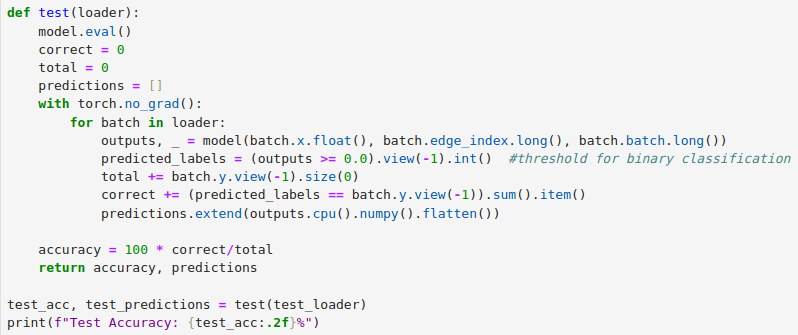
where loss_fn = torch.nn.BCEWithLogitsLoss()
Yes, your code looks correct assuming the model returns logits e.g. from a linear layer.
1 Like
Thank you so much <3.