I want to make an Autoencoder with binary weights at the first layer. You can see attached the network layout:
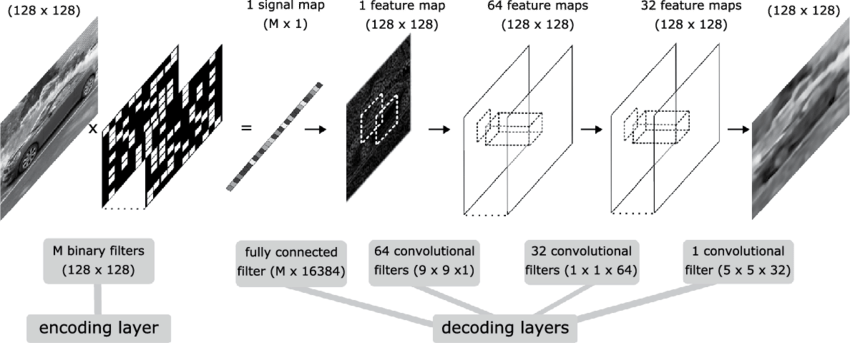
(Source)
I think I have succesfully implemented almost everything except the backward for binary layer. I am still a beginner in NN’s so I really need help to make this network better.
Here are my results right now:

But as you can see this is far from perfect. The problem is that I should also optimize the binary filters to get the best result. Here is a part of my code:
class BinaryFilterLayer(nn.Module):
def __init__(self,number_of_features):
super(BinaryFilterLayer, self).__init__()
self.number_of_features = number_of_features
# Generating the initial binary filters (only 0 and 1)
self.weight = nn.Parameter(torch.randint(high = 2,size=(1,self.number_of_features,128,128)).float())
def forward(self, input):
output = input * self.weight
return output
# here i need the backward but i dont really know how
class Model(nn.Module):
def __init__(self,encoding_dim):
super(Model, self).__init__()
self.encoding_dim = encoding_dim
# Encode
self.binary_filters = BinaryFilterLayer(self.encoding_dim)
# Decode
self.decoder = nn.Sequential(
nn.LayerNorm(self.encoding_dim),
nn.Linear(self.encoding_dim,128*128),
nn.LayerNorm(128*128),
nn.ReLU(),
Reshape(128,128),
nn.Conv2d(1,64,kernel_size= 9,padding=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,32,kernel_size= 1,padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32,1,kernel_size= 5,padding=2),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
def sumfunc(self,x):
x = torch.sum(x,dim=3) # maybe there is an efficient way but this should work well also i guess
x = torch.sum(x,dim=2)
return x/(128*128) # not sure if i need to normalize here but probably not
def forward(self, x):
x = self.binary_filters(x) # multiply with binary layers
x = self.sumfunc(x) # get the sum of each layer
x = self.decoder(x) # decode
return x
Can somebody help me to optimize these binary filters? Or is there a better way to make this network working better?