My environment is:
- pytorch: 1.7.0+cu110
- cuda driver: 455.23.04
- cuda version: 11.1.
- graphic card: 3090
I found that when other people run progorm on card device 0, my program running at any device would stop at model.cuda()/some tensor.cuda(); The nvidia-smi print
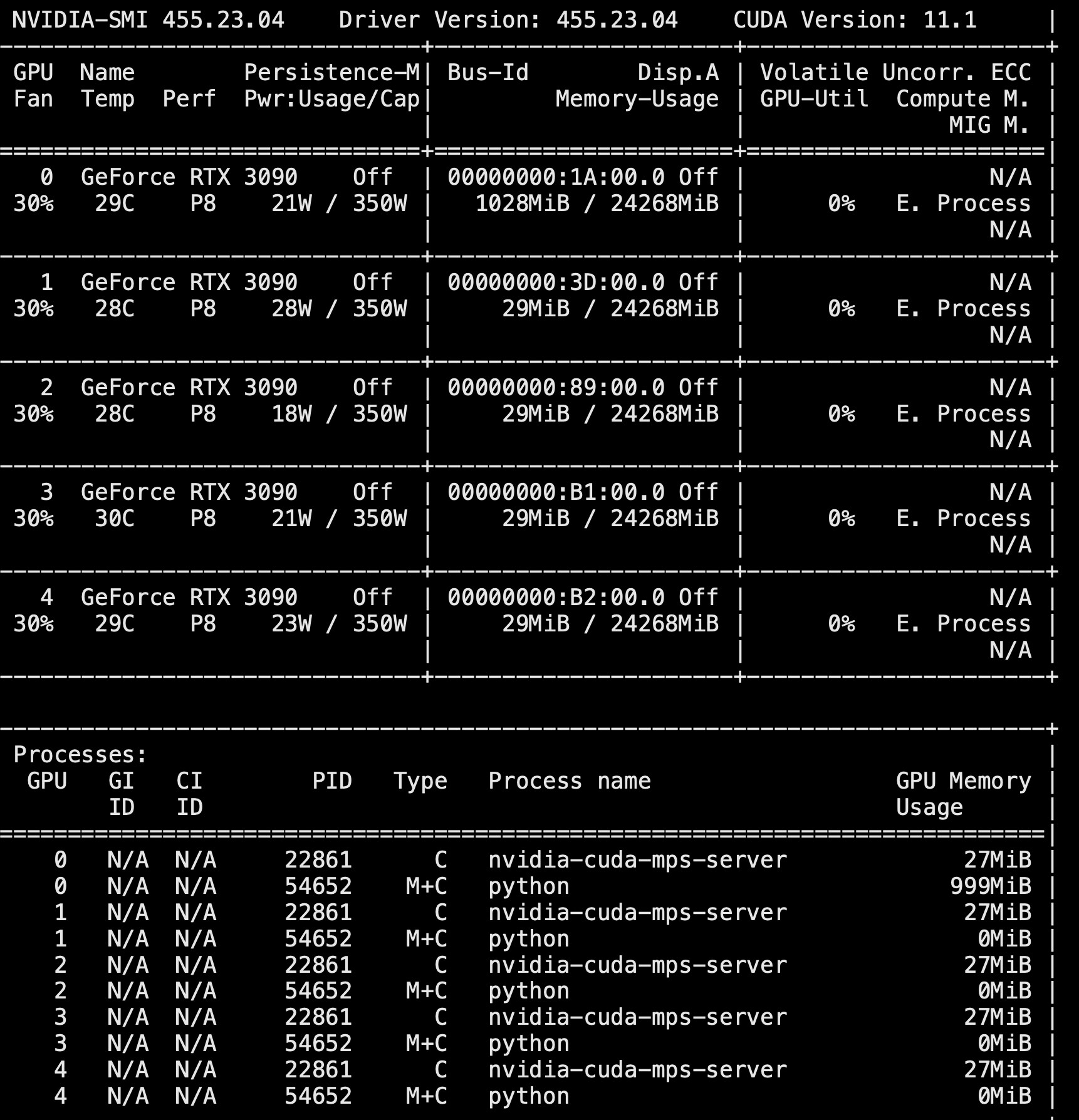
It is also weird that the one who run program on devie 0 would occupy 29Mib memory for each other device.