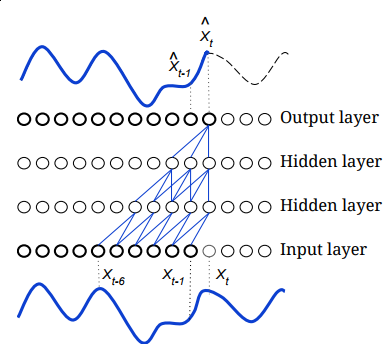
Yeah, one common solution when predicting the first element is to pad the input with zeros and use the padded input to predict Y_0.
Sergei’s post explains it in the context of Wavenet. The first convolution is padded such that the model doesn’t use the current sample to predict the current sample.
After the first convolution, we then have a structure that seems to be using P(Y_i | X_{j<=i}) when in fact it’s really P(Y_i | E_i, X_{i-1}), that is, the probability of the current sample given the embeddings of the current sample and the previous sample used to create the embedding.
I’m abusing notation.