Hello everyone,
I have some fun with comparison of linear algebra in tensorflow and pytorch. One strange thing I notice for cholesky is that when I use GPU mode in Pytorch - CPU (all cores) is still utilized heavily alongside 99% of GPU, meanwhile TensorFlow Cholesky doesn’t use CPU much. It is a bit of concern, because the project which I implemented significantly faster in TensorFlow, it is too early to say that it actually faster, but first stage of debugging, using pytorch bottleneck, showed that torch.potrf takes ~some time to compute. What Pytorch does so that it overloads all CPU cores? How can I alleviate this problem?
Here is some results using script from here Cholesky GPU benchmarks · GitHub
GPU: Nvidia 1080 Ti, 11Gb.
CPU: Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz, 4 cores.
RAM: 32GB
Pytorch: 0.5.0a0+41c08fe
Python: 3.6.6
CUDA: 9.0
Magma: 2.3.0
> python bench_cholesky.py XXX 10000 [10|100]
| | cholesky (avg. sec, 100 times) | cholesky + grads (avg. sec, 10 times) |
|--------------|-------------------------------:|--------------------------------------:|
|torch | 1.31742e+00 | 2.25207e+01 |
|tensorflow | 1.13558e+00 | 2.00329e+01 |
CPU & GPU for TensorFlow and Pytorch runs:
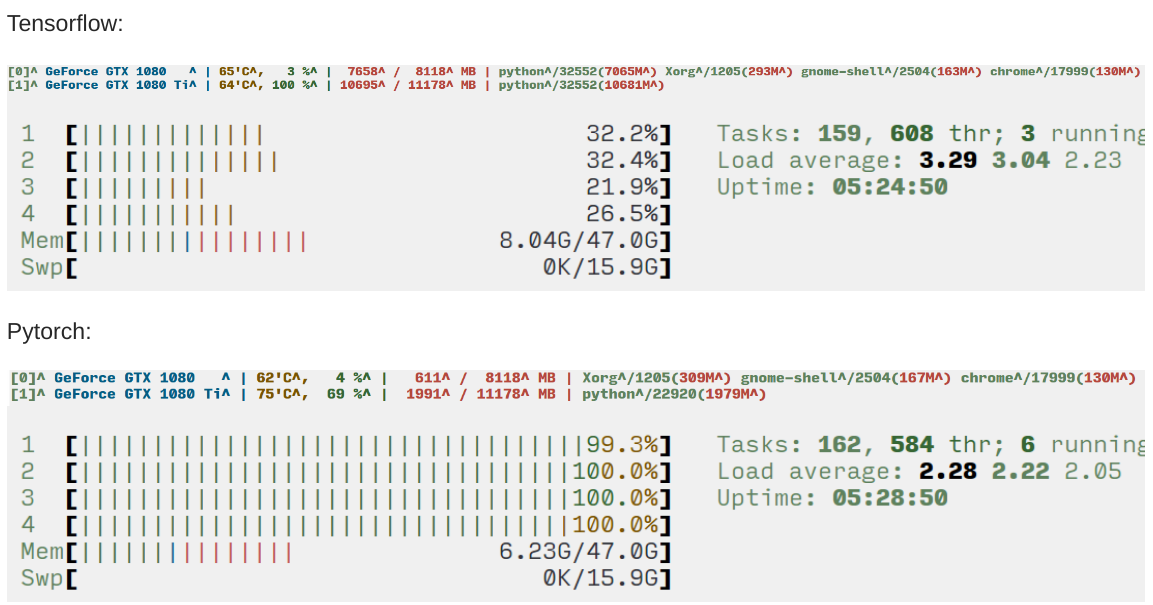
Actually, Pytorch used ~99% of GPU all the time with some fluctuation, when TensorFlow stayed 100% till the end of a test.
Thanks!