Hello,
I currently have a network that is running, but my final outputs are not matching what they should, and I think the issue has to do with my loss function. The network takes in a 1x12 binary vector and outputs a 1x30 vector. Here’s my code:
#Define a Net class that models the architecture described above
#This will be a subclass of the generical nn.Model class
class Net(nn.Module):
#constructor method includes definitions of weight matrices for the layers
#these matrices will be available by calling the parameters() instance function
def __init__(self):
super(Net, self).__init__()
#define the operations y = Wx + b associated with the connection weights
self.item_to_rep = nn.Linear(8, 8) #maps 8 inputs to 8 representation nodes
self.rep_rel_to_hidden = nn.Linear(12, 15) #maps 12 representation & relation nodes to 15 hidden nodes
self.hidden_to_out = nn.Linear(15, 30) #maps 15 hidden nodes to 30 output nodes
self.loss = nn.BCELoss() #uses BCE loss function
#propagates inputs to outputs using current weights in computation
#backward method is not defined in this class - it's incorporated into PyTorch
def forward(self, x):
#split input into item and relation nodes
item = x[:8]
rel = x[8:]
rep = F.relu(self.item_to_rep(item))
temp = torch.cat([rep, rel],-1)
hidden = F.relu(self.rep_rel_to_hidden(temp))
output = F.sigmoid(self.hidden_to_out(hidden))
return output
#main computation
def buildAndTrainNetwork():
net = Net() #initialize network
optimizer = optim.SGD(net.parameters(), lr=0.01) #specifies learning algorithm, rate
targets, x = textToTensor()
#this method isn't done but here's something:
for n in range(5000):
for i in range(len(x[0])):
y = net(x[i]) #forward-propagates inputs to outputs using current weights
optimizer.zero_grad() #clears gradient records to prepare for weights update
error = net.loss(y,targets[i]) #computs output loss for current training instances
error.backward() #triggers the backpropagation of errors
optimizer.step() #updates weights based on backpropagated errors
if n%500 == 0:
print(error.data[0])
print(y,targets[i])
I’ve tried switching to a bunch of different loss functions without having any luck.
Here’s a screenshot of my activation output vs target output after 5,000 epochs:
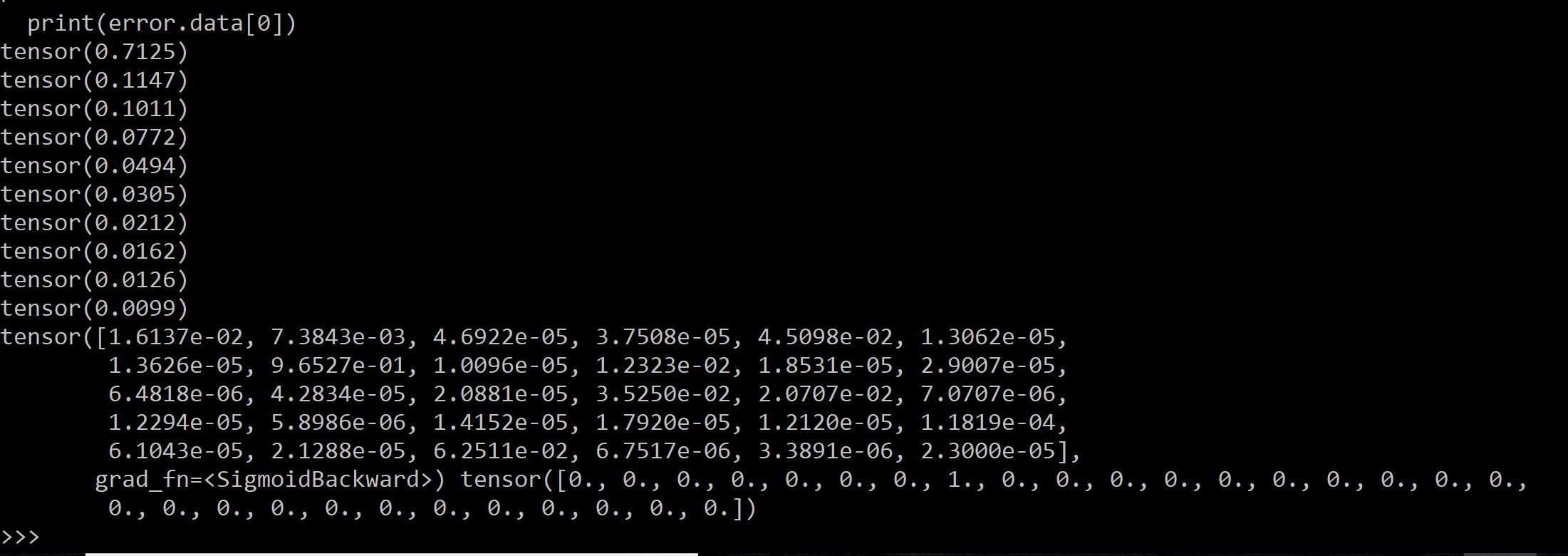
The activation of the 8th node is highest by a lot, but still isn’t close enough to 1.
Not really sure what’s going on here since I’m pretty new, and some insight would be highly appreciated. Thanks!