Short answer: You can use either.
For a bit more understanding, first check the output of output and h_n
output.shape = (seq_len, batch, num_directions * hidden_size), so you get a (context) vector for each item in your sequenceh_n.shape = (num_layers * num_directions, batch, hidden_size)
Now look at the following archtecture – it’s for an LSTM, for a GRU you can simple ignore the c_n:
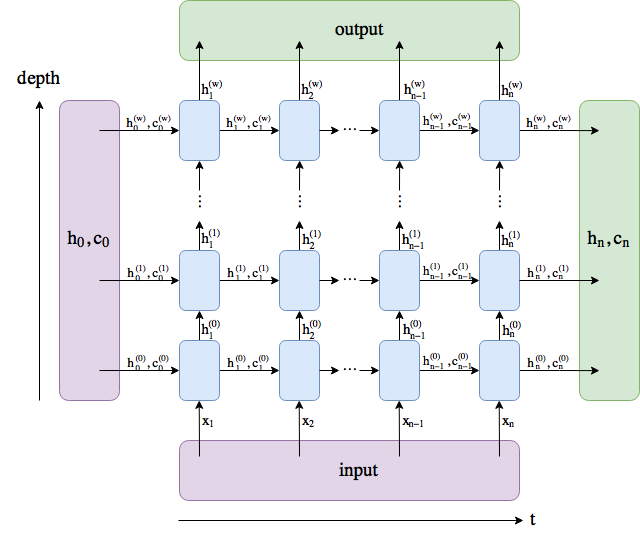
In the basic case where num_layer=1 and bidirectional=False, and you don’t use PackedSequence, then output[-1]=h_n. In other words, h_n is the vector after the last layer and the last sequence item (bidirectional=True makes it more complicated).
Fore Seq2Seq, most people use h_n as context vector since the encoder and decoder often have symmetric architectures (e.g., same number of layers), so they can simple copy h_n between encoder to the decoder.
For classification, I usually use h_n instead of output. The reasons is – as far as I understand – then when you have batches with sequences of different lengths and padding, and use PackedSequence, output[-1] != h_n. It still works, of course, but I experience less accuracy.