Hello,
I implemented a CNN for CIFAR-10 image classification, but my model does not seem to update its weights. I already looked into several threads discussing the same symptoms, but my model seems to have a different problem.
Model
class CNNModel(ImageClassificationBase):
def __init__(self):
super().__init__()
self.network = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2), # output: 64 x 16 x 16
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2), # output: 128 x 8 x 8
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2), # output: 256 x 4 x 4
nn.Flatten(),
nn.Linear(256*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 128),
nn.ReLU(),
nn.Linear(128, 10))
def forward(self, x):
return self.network(x)
The model inherits ImageClassificationBase
class ImageClassificationBase(nn.Module):
def training_step(self, batch, criterion):
images, labels = batch
images = images.to(device)
labels = labels.to(device)
out = self(images) # Generate predictions
loss = criterion(out, labels) # Calculate loss
return loss
def validation_step(self, batch, criterion):
images, labels = batch
images = images.to(device)
labels = labels.to(device)
out = self(images) # Generate predictions
loss = criterion(out, labels) # Calculate loss
acc = accuracy(out, labels) # Calculate accuracy
return {'val_loss': loss.detach(), 'val_acc': acc}
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
batch_accs = [x['val_acc'] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies
return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(
epoch+1, result['train_loss'], result['val_loss'], result['val_acc']))
Training Loop
def fit(epochs, model, train_loader, val_loader, optimizer, criterion):
history = []
for epoch in range(epochs):
# Training phase
model.train()
train_losses = []
for batch in train_loader:
loss = model.training_step(batch, criterion)
train_losses.append(loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Validation phase
result = evaluate(model, val_loader, criterion)
result['train_loss'] = torch.stack(train_losses).mean().item()
model.epoch_end(epoch, result)
history.append(result)
return history
Further code used for training
def accuracy(output, labels):
_, predictions = torch.max(output, dim=1)
return torch.tensor(torch.sum(predictions == labels).item() / len(predictions))
def evaluate(model, val_loader, criterion):
model.eval()
outputs = [model.validation_step(batch, criterion) for batch in val_loader]
return model.validation_epoch_end(outputs)
I use CrossEntropyLoss as criterion
criterion = nn.CrossEntropyLoss()
and Adam as optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay, eps=eps)
In some other thread someone said to look at
list(model.parameters())[0].grad
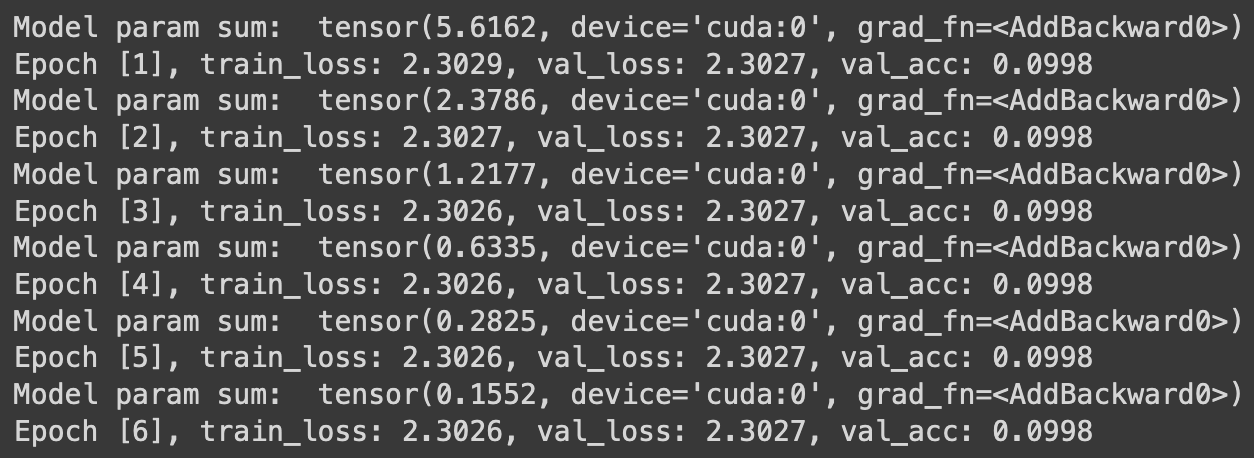
which returns arrays completly filled with zeros.
Accuracy and loss stays the same over a couple of epochs (the tensor-list is the model prediction for individual images).
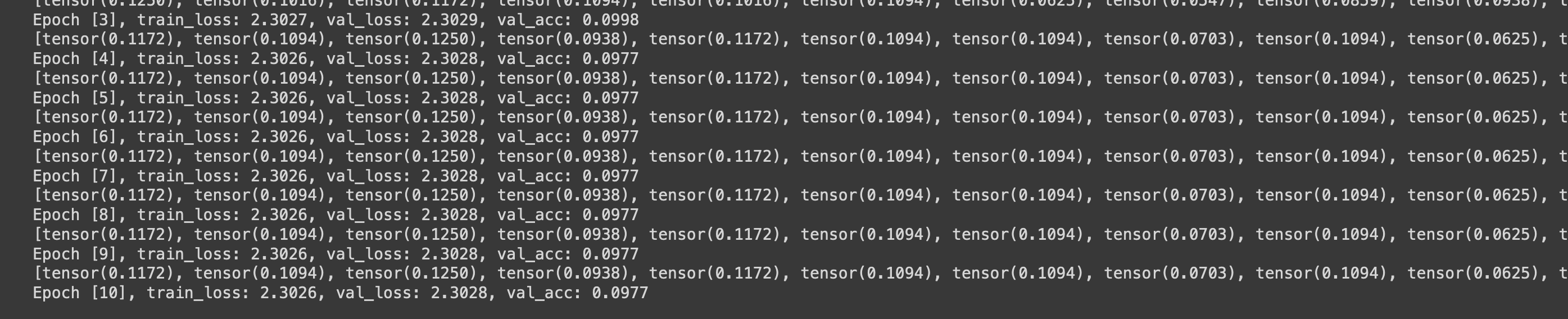
In some other threads the problem was a combination of Softmax and CrossEntropyLoss - which is not the problem in my case as i am using ReLU as last activation layer.
I already tried SGD as well, both optimizers with different learning rates (0.001-0.0001). Nothing worked.
I really have no idea where the problem is…
Thanks for the help!