I trained a classifier and saved the model using:
torch.save(model, "/home/zaianir/Documents/code/tuto/classif/MNIST_model.pth")
I’m trying to train a new classifier on top of the pretrained saved model without its last layer.
I want to train only the parameters of the new added layers (I don’t want to update the saved parameters).
Here is some of my code:
class VAE2(nn.Module):
def __init__(self):
super(VAE2, self).__init__()
self.fc3=nn.Linear(50,20)
self.fc4=nn.Linear(20,10)
def forward(self, x):
x=F.relu(self.fc3(x))
x=F.relu(self.fc4(x))
x=F.log_softmax(x)
return x
class VAE(nn.Module):
def __init__(self, VAE1, VAE2):
super(VAE, self).__init__()
self.VAE1=VAE1
self.VAE2=VAE2
def forward(self):
x=self.VAE1
x=self.VAE2(x)
return x
def loss_function(inp, target):
l=F.nll_loss(inp, target)
return l
def train(train_dl, model, epoch_nb,lr1):
optimizer=torch.optim.Adam(model.parameters(), lr=lr1)
train_loss1=[]
for epoch in range(1,epoch_nb):
model.train()
train_loss=0.0
for idx, (data, label) in enumerate(train_dl):
data, label= data.to(device), label.to(device)
out=model(data)
loss=loss_function(out,data)
train_loss+=loss.item()
model.zero_grad()
loss.backward()
optimizer.step()
av_loss= train_loss / len(train_dl.dataset)
print('Epoch: {} Average loss: {:.4f}'.format(
epoch, av_loss))
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=128, shuffle=True, **kwargs)
VAE1 = torch.load("/home/zaianir/Documents/code/tuto/classif/MNIST_model.pth")
VAE2_model=VAE2().to(device)
model=VAE(VAE1, VAE2_model)
epoch=30
learning_rate=0.001
train(train_loader, model, epoch, learning_rate)
Here are the different layers of my loaded model (VAE1):
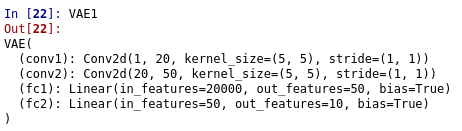
I’m new to pytorch and don’t know how to proceed. Is my approach correct?
Thank you for your help.