I would like to use pertained models such as Roberta as an encoder and GPT2 as a decoder, but each one has a different tokenizer. So how can I pass the output of Roberta as input to GPT2?
Actually, they both use Byte Pair encoding with the same vocabulary, no? ROBERTA != BERT … So, this seems possible. However, GPT2’s decoder blocks don’t have encoder-decoder self attention: will you add this in and pre train it? Or, will you use ROBERTA to feed a prefix to GPT2 and then start generating with it?
Thanks for your reply.
I will use Roberta embedding to feed it to pretrained GPT2 model… But the problem that pertained model has embedding layer which require indices as input … so How I can use Roberta embedding as input to GPT2 ?
Just some ideas … So I’m thinking you need to add an encoder-decoder attention layer to GPT2? Basically, GPT2 has no encoder, so it has no encoder-decoder attention. You’d need to insert that in. The input to GPT2 would still be tokens, and it gets the embeddings for those tokens and passed them up. As these embedding travel up, there is a masked These would then be updated eventually using the hidden states passed from Roberta. Basically, (at a high level) in the picture below ROBERTA is the left side and GPT2 is the right side, but GPT2 has no encoder-decoder attention. You might also figure out a way to take the embeddings for each of the tokens to GPT2 and swap in the ROBERTA vectors, for each token. This would also take some digging. You might need to grab parts of the model and do this in PyTorch more directly than using the hugging face APIS. I.e. usually you add a head on top, you now want to kind of add a preprocessing step to the GPT2 model, on the bottom.
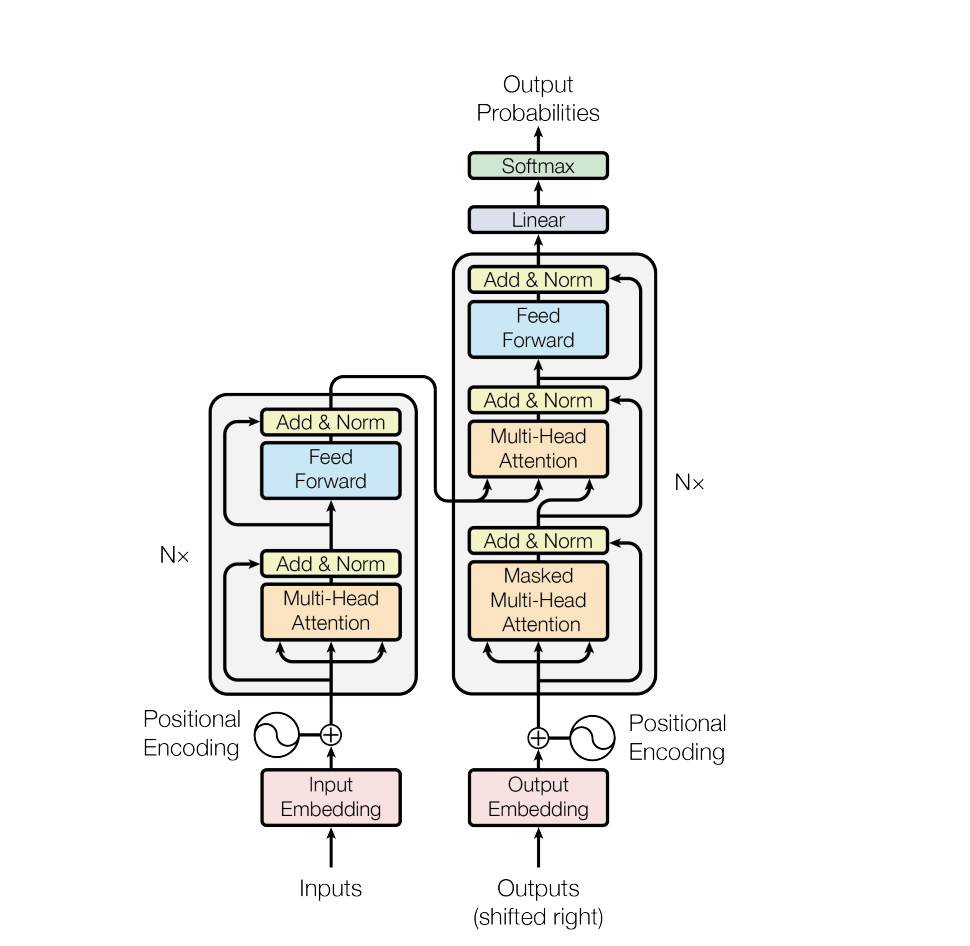
So, can I implement it as follows:
config_decoder = AutoConfig.from_pretrained(“gpt2”, is_decoder=True, add_cross_attention= True)
model_dec = GPT2LMHeadModel.from_pretrained(“gpt2”, config=config_decoder)
model_rob = RobertaModel.from_pretrained(“roberta-base”, output_hidden_states= True)
out_rob = model_rob(**inputs)
out_rob2 = out_rob[0]
out_gpt = model_dec(inputs_embeds = out_rob2, labels=inputs[‘input_ids’], encoder_hidden_states=out_rob2)
Is this code correct?