Hi @ptrblck,
Thank you for your reply. In my case, currently, it seems there is a little improvement in the overall accuracy when TL = True.
Hi @ptrblck,
Thank you for your reply. In my case, currently, it seems there is a little improvement in the overall accuracy when TL = True.
Is the fine-tuning use case converging at least a bit faster than the randomly initialized model?
Hi @ptrblck,
It depends on the network to converge faster and also to improve the accuracy. I used Early Stopping. Below I show some results, column Stop - Epoch identifies the epoch when training ended due to Early Stopping.
Hence, sometimes TL = True improves the accuracy and ends earlier and sometimes improves and ends later. And sometimes it does not improve the accuracy at all. Any thoughts?
Best.
Hi Guys,
I’m using yolov3 and darknet53 architecture and I want to implement the method of Early fusion.
I already concatenate the 2 inputs; each input has the first block of darknet53 architecture and then I concatenated the 2 inputs together and then I’m trying to add the rest of the model, like this figure :
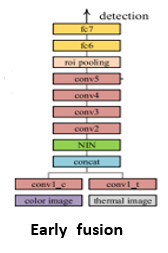
My solution is like here :
out_rgb = self.model[:3](in_rgb)
out_rgb = torch.randn(1, 32, 32, 32)
print("out_rgb",out_rgb.shape)
out_ther = self.model[:3](in_ther)
out_ther = torch.randn(1, 32, 32, 32)
print("out_ther",out_ther.shape)
out_cat = torch.cat((out_rgb,out_ther),1)
print("concat",out_cat.shape)
out = self.model[3:](out_cat)
print("model",out.shape)
return out
But I have error :
out_rgb torch.Size([1, 32, 32, 32])
out_ther torch.Size([1, 32, 32, 32])
concat torch.Size([1, 64, 32, 32])
Traceback (most recent call last):
File "train.py", line 622, in <module>
train(hyp, opt, device, tb_writer, wandb)
File "train.py", line 79, in train
model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc).to(device) # create
File "/content/drive/My Drive/yolov3_v0/models/yolo.py", line 103, in __init__
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, 3, s, s),torch.zeros(1, 3, s, s))]) # forward
File "/content/drive/My Drive/yolov3_v0/models/yolo.py", line 166, in forward
out = self.model[3:](out_cat)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/container.py", line 119, in forward
input = module(input)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/content/drive/My Drive/yolov3_v0/models/common.py", line 151, in forward
return torch.cat(x, self.d)
TypeError: cat() received an invalid combination of arguments - got (Tensor, int), but expected one of:
* (tuple of Tensors tensors, name dim, *, Tensor out)
* (tuple of Tensors tensors, int dim, *, Tensor out)
How should I correct that please?
Based on the error message torch.cat(x, self.d) is failing, since x seems to be a tensor, while self.d an int. Assuming self.d defines the dimension and is thus rightfully passed as an int the error is raised by x being a tensor instead of a tuple of tensors.
I changed torch.cat(x, self.d) to torch.cat(tuple(x), self.d).
But i still have a problem RuntimeError: Expected 4-dimensional input for 4-dimensional weight [256, 768, 1, 1], but got 3-dimensional input of size [256, 4, 4] instead. I used the squeeze function to remove the fourth dimension but it didn’t work.
out_ther = self.model[:3](in_ther)
out_ther = torch.randn(1, 32, 32, 32)
print("out_ther",out_ther.shape)
print(type(out_ther))
out_cat = torch.cat((out_rgb,out_ther),dim=1)
print("concat",out_cat.shape)
**out_cat = torch.squeeze(out_cat,1)**
print(type(out_cat))
out = self.model[3:](out_cat)
print("model",out.shape)
print(type(out))
return out
The new error points to the 4-dimensional weight of what seems to be an nn.Conv2d layer.
You would thus have to pass either 4-dimensional inputs or use nn.Conv1d layers instead, if you want to keep using 3-dimensional activation tensors (or unsqueeze a dimension, assuming the kernel of the conv layer is not larger than 1).
I add out_cat = out_cat.unsqueeze(1) but this function add 2-dim not 1-dim , RuntimeError: Expected 4-dimensional input for 4-dimensional weight [128, 64, 3, 3], but got 5-dimensional input of size [1, 1, 64, 32, 32] instead
out_rgb = self.model[:3](in_rgb)
out_rgb = torch.randn(1, 32, 32, 32)
print("out_rgb",out_rgb.shape)
#torch.nn.Upsample(size=(50, 50))(torch.rand(1, 3, 64, 64))
out_ther = self.model[:3](in_ther)
out_ther = torch.randn(1, 32, 32, 32)
print("out_ther",out_ther.shape)
out_cat = torch.cat((out_rgb,out_ther),dim=1)
print("concat",out_cat.shape)
print(type(out_cat))
out_cat = out_cat.unsqueeze(1)
out = self.model[3:](out_cat)
print("model",out.shape)
print(type(out))
# out = out.unsqueeze(1)
return out
unsqueeze will add a single dimension as seen here:
out_cat = torch.randn(1, 2, 3)
print(out_cat.size(), out_cat.dim())
> torch.Size([1, 2, 3]) 3
out_cat = out_cat.unsqueeze(1)
print(out_cat.size(), out_cat.dim())
> torch.Size([1, 1, 2, 3]) 4
so I assume your inputs might have a different number of dimensions, where some might be missing one dimension?
I think , It’s something wrong in out = self.model[3:](out_cat) but i don’t know what exactly.
out_rgb = torch.randn(1, 32, 32, 32)
print(out_rgb.size(), out_rgb.dim())
> torch.Size([1, 32, 32, 32]) 4
out_ther = torch.randn(1, 32, 32, 32)
print(out_ther.size(), out_ther.dim())
> torch.Size([1, 32, 32, 32]) 4
out_cat = torch.cat((out_rgb,out_ther),dim=1)
print(out_cat.size(), out_cat.dim())
> torch.Size([1, 64, 32, 32]) 4
out = self.model[3:](out_cat)
print(out.size(), out.dim())
> File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/conv.py", line 396, in _conv_forward
self.padding, self.dilation, self.groups)
RuntimeError: Expected 4-dimensional input for 4-dimensional weight [128, 64, 3, 3], but got 3-dimensional input of size [1, 1, 64, 32, 32] instead
and when i add out_cat = out_cat.unsqueeze(1) or out= out.unsqueeze(1) i have :
File “/usr/local/lib/python3.7/dist-packages/torch/nn/modules/conv.py”, line 396, in _conv_forward
self.padding, self.dilation, self.groups)
RuntimeError: Expected 4-dimensional input for 4-dimensional weight [128, 64, 3, 3], but got 5-dimensional input of size [1, 1, 64, 32, 32] instead
Could you post a minimal, executable code snippet, which would reproduce this issue, please?
import argparse
import logging
import sys
from copy import deepcopy
from pathlib import Path
import numpy
sys.path.append('./') # to run '$ python *.py' files in subdirectories
logger = logging.getLogger(__name__)
from models.common import *
from models.experimental import MixConv2d, CrossConv
from utils.autoanchor import check_anchor_order
from utils.general import make_divisible, check_file, set_logging
from utils.torch_utils import time_synchronized, fuse_conv_and_bn, model_info, scale_img, initialize_weights, \
select_device, copy_attr
try:
import thop # for FLOPS computation
except ImportError:
thop = None
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=4, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(out, self.no * self.na, 1) for out in ch) # output conv
def forward(self, out):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
out[i] = self.m[i](out[i]) # conv
bs, _, ny, nx = out[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
out[i] = out[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != out[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(out[i].device)
y = out[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(out[i].device)) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return out if self.training else (torch.cat(z, 1), out)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
class Model(nn.Module):
def __init__(self, cfg='yolov3.yaml', ch=3, nc=None): # model, input channels, number of classes
super(Model, self).__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg) as f:
self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
logger.info('Overriding model.yaml nc=%g with nc=%g' % (self.yaml['nc'], nc))
self.yaml['nc'] = nc # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
# print([x.shape for x in self.forward(torch.zeros(1, ch, 64, 64))])
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 256 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, 3, s, s),torch.zeros(1, 3, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
# Init weights, biases
initialize_weights(self)
self.info()
logger.info('')
def forward(self, in_rgb,in_ther, augment=False, profile=False):
if augment:
img_size = in_rgb.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi1 = scale_img(in_rgb.flip(fi) if fi else in_rgb, si, gs=int(self.stride.max()))
yi1 = self.forward_once(xi1)[0] # forward
xi2 = scale_img(in_ther.flip(fi) if fi else in_ther, si, gs=int(self.stride.max()))
yi2 = self.forward_once(xi2)[1] # forward
# cv2.imwrite('img%g.jpg' % s, 255 * xi[0].numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi1[..., :4] /= si # de-scale
yi2[..., :4] /= si # de-scale
if fi == 2:
yi1[..., 1] = img_size[0] - yi1[..., 1] # de-flip ud
yi2[..., 1] = img_size[0] - yi2[..., 1] # de-flip ud
elif fi == 3:
yi1[..., 0] = img_size[1] - yi1[..., 0] # de-flip lr
yi2[..., 0] = img_size[1] - yi2[..., 0] # de-flip lr
y.append(yi1,yi2)
return torch.cat(y, 1), None # augmented inference, train
else:
out_rgb = self.model[:3](in_rgb)
out_rgb = torch.randn(1, 32, 32, 32)
print(out_rgb.size(), out_rgb.dim())
print("out_rgb",out_rgb.shape)
#torch.nn.Upsample(size=(50, 50))(torch.rand(1, 3, 64, 64))
out_ther = self.model[:3](in_ther)
out_ther = torch.randn(1, 32, 32, 32)
print("out_ther",out_ther.shape)
out_cat = torch.cat((out_rgb,out_ther),dim=1)
print("concat",out_cat.shape)
out = self.model[3:](out_cat)
out= out.unsqueeze(1)
print("model",out.shape)
print(type(out))
return out # single-scale inference, train
def forward_once(self, in_rgb,in_ther, profile=False):
y, dt = [], [] # outputs
for i,m in enumerate (self.model[:27]):
#print("bloc 1 :",i,m)
if(self.model[:3]):
print("model 3",self.model[:3])
m1=m
m2=m
# print("self.model bloc",self.model[:3]) #conv, conv, Bottleneck
if m1.f != -1 and m2.f != -1 : # if not from previous layer
print("m1",m1)
print("m2",m2)
in_rgb = y[m1.f] if isinstance(m1.f, int) else [in_rgb if j == -1 else y[j] for j in m1.f] # from earlier layers
in_ther = y[m2.f] if isinstance(m2.f, int) else [in_ther if j == -1 else y[j] for j in m2.f] # from earlier layers
if profile:
o1 = thop.profile(m1, inputs=(in_rgb,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPS
o2 = thop.profile(m2, inputs=(in_ther,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPS
t = time_synchronized()
for _ in range(10):
_ = m1(in_rgb)
_ = m2(in_ther)
dt.append((time_synchronized() - t) * 100)
print('%10.1f%10.0f%10.1fms %-40s' % (o1, m1.np, dt[-1], m1.type))
# print("bloc1***",m)
in_rgb = m1(in_rgb) # run
print("in_rgb",in_rgb.shape)
in_ther = m2(in_ther)
print("in_ther",in_ther.shape)
out = torch.cat((in_rgb,in_ther),dim=1)
print("out",out)
y.append(out if m.i in self.save else None) # save output
#if self.model[3:] :
# print(" blocs",m)
if profile:
print('%.1fms total' % sum(dt))
return in_rgb,in_ther
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
print(('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# print('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
print('Fusing layers... ')
for m in self.model.modules():
if type(m) is Conv and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.fuseforward # update forward
self.info()
return self
def nms(self, mode=True): # add or remove NMS module
present = type(self.model[-1]) is NMS # last layer is NMS
if mode and not present:
print('Adding NMS... ')
m = NMS() # module
m.f = -1 # from
m.i = self.model[-1].i + 1 # index
self.model.add_module(name='%s' % m.i, module=m) # add
self.eval()
elif not mode and present:
print('Removing NMS... ')
self.model = self.model[:-1] # remove
return self
def autoshape(self): # add autoShape module
print('Adding autoShape... ')
m = autoShape(self) # wrap model
copy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributes
return m
def info(self, verbose=False, img_size=640): # print model information
model_info(self, verbose, img_size)
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, Bottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3]:
c1, c2 = ch[f], args[0]
# Normal
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1.75 # exponential (default 2.0)
# e = math.log(c2 / ch[1]) / math.log(2)
# c2 = int(ch[1] * ex ** e)
# if m != Focus:
c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
# Experimental
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1 + gw # exponential (default 2.0)
# ch1 = 32 # ch[1]
# e = math.log(c2 / ch1) / math.log(2) # level 1-n
# c2 = int(ch1 * ex ** e)
# if m != Focus:
# c2 = make_divisible(c2, 8) if c2 != no else c2
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3]:
args.insert(2, n)
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x if x < 0 else x + 1] for x in f])
elif m is Detect:
args.append([ch[x + 1] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f if f < 0 else f + 1] * args[0] ** 2
elif m is Expand:
c2 = ch[f if f < 0 else f + 1] // args[0] ** 2
else:
c2 = ch[f if f < 0 else f + 1]
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='models/yolov3.yaml', help='model.yaml')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
opt = parser.parse_args()
opt.cfg = check_file(opt.cfg) # check file
set_logging()
device = select_device(opt.device)
# Create model
model = Model(opt.cfg).to(device)
model.train()
!python train.py --img 640 --batch 7 --epochs 1 --data FlirRGB.yaml --weights yolov3.pt```
``` torch.Size([1, 32, 32, 32]) 4
out_rgb torch.Size([1, 32, 32, 32])
out_ther torch.Size([1, 32, 32, 32])
concat torch.Size([1, 64, 32, 32])
Traceback (most recent call last):
File "train.py", line 622, in <module>
train(hyp, opt, device, tb_writer, wandb)
File "train.py", line 79, in train
model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc).to(device) # create
File "/content/drive/MyDrive/yolov3_v0/models/yolo.py", line 98, in __init__
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, 3, s, s),torch.zeros(1, 3, s, s))]) # forward
File "/content/drive/MyDrive/yolov3_v0/models/yolo.py", line 154, in forward
out = self.model[3:](out_cat)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/container.py", line 119, in forward
input = module(input)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/content/drive/MyDrive/yolov3_v0/models/common.py", line 37, in forward
return self.act(self.bn(self.conv(x)))
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/conv.py", line 399, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/conv.py", line 396, in _conv_forward
self.padding, self.dilation, self.groups)
RuntimeError: Expected 4-dimensional input for 4-dimensional weight [128, 64, 3, 3], but got 5-dimensional input of size [1, 1, 64, 32, 32] instead ```@ptrblck
This is what I’ve been trying to do but I am using a ResNet18 model with additional layers as can be seen here (Adding layers to ResNet18 gives RuntimeError error - #4 by duddal) but I am getting a RuntimeError: Given groups=1, weight of size [128, 127, 3, 3], expected input[1, 128, 44, 120] to have 127 channels, but got 128 channels instead which is weird because I checked the in_channels and out_channels and doesn’t seem wrong to me. Maybe I am missing something. Do you have any idea perhaps?
Based on your code snippet:
class NewLayers(nn.Module):
def __init__(self, layers, last_in_channels, last_out_channels, stride=(1, 1), dilation=(1, 1)):
super(NewLayers, self).__init__()
# layers: [5, 8]
# last_in_channels: 128
# last_out_channels: 256
# Need two _make_layers() with blocks 5 and 8 respectively
self.intermediate1_layers = self._make_layer(BasicBlock2, layers[0], in_channels=128, out_channels=128)
self.intermediate2_layers = self._make_layer(BasicBlock3, layers[1], in_channels=128, out_channels=128)
self.conv = nn.Conv2d(in_channels=last_in_channels,
out_channels=last_out_channels,
kernel_size=(5, 5),
padding=(2, 0),
dilation=dilation,
stride=stride)
self.batchnorm = nn.BatchNorm2d(last_out_channels)
self.relu = nn.ReLU(inplace=True)
# A new conv layer is added
self.last_conv =nn.Conv2d(in_channels=127,
out_channels=128,
kernel_size=(3, 3),
padding=(1, 1),
stride=stride,
dilation=dilation)
def _make_layer(self, block, blocks, in_channels, out_channels): # blocks = 5 and blocks = 8
layers = []
for _ in range(1, blocks+1): # because in python last index is not considered, hence + 1
layers.append(block(in_channels, out_channels))
return nn.Sequential(*layers)
# changes are made in this method
def forward(self, img, dep):
out = self.intermediate1_layers(img)
out = self.intermediate2_layers(out)
out = self.conv(out)
out = self.batchnorm(out)
out = self.relu(out)
concat = torch.cat((out, dep), dim=1)
out = self.last_conv(concat)
return out
you are defining in_channels=127 and out_channels=128 while also concatenating out with dep, which might have 128 channels afterwards, so you would need to check the shape of concat and adapt self.last_conv if necessary.
Hi, I am also trying to concatenate layer output with additional input data but strangely I am getting an index error when I begin training. Here are snippets of the code and error output:
class Net(nn.Module):
def __init__(self, n_class):
super().__init__()
self.n_class = n_class
self.conv1 = nn.Conv2d(3, 16, 3, 1)
self.norm1= nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
#self.pool1 = nn.MaxPool2d(2, stride=2)
self.conv2 = nn.Conv2d(16, 32, 3, 1)
self.norm2= nn.BatchNorm2d(32)
self.relu = nn.ReLU(inplace=True)
self.pool = nn.MaxPool2d(2, stride=2)
self.drop = nn.Dropout2d(0.6)
self.fc1 = nn.Linear(508032,512)
self.fc2 = nn.Linear(512+1, 5)
# Defining the forward pass with the variable x representing our input data
def forward(self, inp, depth):
# First Block
x = self.pool(self.relu(self.norm1(self.conv1(inp))))
# Second Block
x = self.pool(self.relu(self.norm2(self.conv2(x))))
# Fully connected layer
#x = x.view(inp.shape[0],-1)
#x = x.view(-1)
x = torch.flatten(x, start_dim=0, end_dim=-1)
x = self.fc1(x)
print(x.shape)
print(depth.shape)
x = torch.cat((x,depth),dim = 0)
x = self.relu(x)
x = self.fc2(x)
return x
model = Net(n_class=5)
criterion = torch.nn.CrossEntropyLoss()
n_class=5
optimizer = torch.optim.Adam(model.parameters())
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min' if n_class > 1 else 'max', patience=2)
totEpochs = 1
for ep in range(totEpochs):
val_loss = 0
with tqdm(total=len(valset), desc=f'Validation', unit='img') as pbar:
for batch in validLoader:
with torch.no_grad():
img = batch['image']
label = batch['label']
depth = batch['depth']
net_pred = model(img,depth)
loss = criterion(net_pred, label)
val_loss += loss.item()
pbar.set_postfix(**{'Loss (validation)': loss.item()})
#calculate validation aaccuracy
pred = torch.argmax(net_pred, dim=1)
correct_tensor = pred.eq(label)
accuracy = torch.mean(correct_tensor.type(torch.FloatTensor))
# Multiply average accuracy times the number of examples
pbar.update(img.shape[0])
scheduler.step(val_loss / len(valset))
pbar.set_postfix(**{'Average Loss': val_loss / len(valset)})
IndexError Traceback (most recent call last)
<ipython-input-22-4663b18cecf5> in <module>
9 depth = batch['depth']
10 net_pred = model(img,depth)
---> 11 loss = criterion(net_pred, label)
12 val_loss += loss.item()
13
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\modules\loss.py in forward(self, input, target)
1046 assert self.weight is None or isinstance(self.weight, Tensor)
1047 return F.cross_entropy(input, target, weight=self.weight,
-> 1048 ignore_index=self.ignore_index, reduction=self.reduction)
1049
1050
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\functional.py in cross_entropy(input, target, weight, size_average, ignore_index, reduce, reduction)
2691 if size_average is not None or reduce is not None:
2692 reduction = _Reduction.legacy_get_string(size_average, reduce)
-> 2693 return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
2694
2695
~\AppData\Local\Programs\Python\Python37\lib\site-packages\torch\nn\functional.py in log_softmax(input, dim, _stacklevel, dtype)
1670 dim = _get_softmax_dim("log_softmax", input.dim(), _stacklevel)
1671 if dtype is None:
-> 1672 ret = input.log_softmax(dim)
1673 else:
1674 ret = input.log_softmax(dim, dtype=dtype)
IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
This error is raised in F.cross_entropy, as the model output is expected to have at least 2 dimensions (internally F.log_sotmax(output, dim=1) will be used and will fail otherwise):
F.cross_entropy(torch.randn(10, 2), torch.randint(0, 2, (10,))) # works
F.cross_entropy(torch.randn(10), torch.randint(0, 2, (10,)))
> IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
@ptrblck , i want to use the same thing, however, metadata for my images is categorical. I am using nn.Embedding layer to convert categorical data as follows:
torch.manual_seed(1)
embed_dict = {}
word_to_ix = {"F": 0, "M": 1}
embeds = nn.Embedding(2, 5) # 2 words in vocab, 5 dimensional embeddings
for i, value in enumerate(word_to_ix.keys()):
lookup_tensor = torch.tensor([word_to_ix[value]], dtype=torch.long)
embed_dict[value] = embeds(lookup_tensor)
print(hello_embed)
Here the embedding would be generated for F and M ?
Note Since it is an image classification problem, not an NLP problem, I only want to use the encoded vector of fixed categories in metadata to be used as a feature to aid the final image classification. I would not need to learn the embedding during training right? And can you please check that is this the correct way of generating embedding using nn.Embedding layer?
You are generating the feature vector for both since you are iterating the word_to_idx dict.
Why would you not need to train the embedding?
Currently each categorical input is assigned to a random feature vector, which doesn’t sound really useful by itself.
Hello sir.
I’m trying to implement a kind of similar network, where adding Leaner layers to the end of CNN. Here, I’m concatenating coordinate points to output of CNN layers. However, when I training the model only weights and biases of Linear layers are changing, and weights and biases of Conv3d layers are always None. Would you please help me with this?
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import math
import warnings
from torch.autograd import Variable
class CNN_FC(nn.Module):
def __init__(self, in_features=2, out_features=3, nf=13,
activation=torch.nn.Tanh, cnn_activation=torch.nn.ReLU):
super(CNN_FC, self).__init__()
self.nf = nf
self.in_features = in_features
self.out_features = out_features
self.activ = activation()
self.cnn_activ = cnn_activation()
self.conv_in = nn.Conv3d(self.in_features, self.nf, kernel_size=(2, 2, 1), stride=(1, 1, 1), padding='valid')
self.conv11 = nn.Conv3d(self.nf, self.nf*2, kernel_size=(2, 2, 1), stride=(1, 1, 1), padding='same')
self.conv12 = nn.Conv3d(self.nf*2, self.nf*3, kernel_size=(2, 2, 1), stride=(1, 1, 1), padding='same')
self.conv13 = nn.Conv3d(self.nf*3, self.nf*6, kernel_size=(2, 2, 1), stride=(1, 1, 1), padding='same')
self.conv14 = nn.Conv3d(self.nf*6, self.nf*13, kernel_size=(2, 2, 1), stride=(1, 1, 1), padding='same')
self.convs = [self.conv_in, self.conv11, self.conv12, self.conv13, self.conv14]
self.convs = nn.ModuleList(self.convs)
self.maxpool11 = nn.MaxPool3d(kernel_size=(2, 2, 1), stride=(2, 2, 1), padding=0, dilation=1, ceil_mode=False)
self.maxpool12 = nn.MaxPool3d(kernel_size=(2, 2, 1), stride=(2, 2, 1), padding=0, dilation=1, ceil_mode=False)
self.maxpool13 = nn.MaxPool3d(kernel_size=(2, 2, 1), stride=(2, 2, 2), padding=0, dilation=1, ceil_mode=False)
self.maxpool14 = nn.MaxPool3d(kernel_size=(2, 2, 1), stride=(1, 1, 2), padding=0, dilation=1, ceil_mode=False)
self.maxpools = [self.maxpool11, self.maxpool12, self.maxpool13, self.maxpool14]
self.maxpools = nn.ModuleList(self.maxpools)
self.flatten1 = nn.Flatten()
self.flatten = [self.flatten1]
self.flatten = nn.ModuleList(self.flatten)
self.fc0 = nn.Linear(679, nf*64)
self.fc1 = nn.Linear(nf*64 , nf*32)
self.fc2 = nn.Linear(nf*32 , nf*16)
self.fc3 = nn.Linear(nf*16 , nf*8)
self.fc4 = nn.Linear(nf*8 , nf*4)
self.fc5 = nn.Linear(nf*4, out_features)
self.fc = [self.fc0, self.fc1, self.fc2, self.fc3, self.fc4, self.fc5]
self.fc = nn.ModuleList(self.fc)
def forward(self, c, t, y, x):
c = self.conv_in(c)
c = self.cnn_activ(c)
c = self.conv11(c)
c = self.cnn_activ(c)
c = self.maxpool11(c)
c = self.conv12(c)
c = self.cnn_activ(c)
c = self.maxpool12(c)
c = self.conv13(c)
c = self.cnn_activ(c)
c = self.maxpool13(c)
c = self.conv14(c)
c = self.cnn_activ(c)
c = self.maxpool14(c)
c = self.flatten1(c)
# print(c.shape)
c = c.unsqueeze(1)
c = c.repeat(1,int(x.shape[1]),1)
c = Variable(c, requires_grad=True)
x_tmp = torch.cat((c, t, y, x), dim=-1)
x_tmp = self.fc0(x_tmp)
x_tmp = self.activ(x_tmp)
x_tmp = self.fc1(x_tmp)
x_tmp = self.activ(x_tmp)
x_tmp = self.fc2(x_tmp)
x_tmp = self.activ(x_tmp)
x_tmp = self.fc3(x_tmp)
x_tmp = self.activ(x_tmp)
x_tmp = self.fc4(x_tmp)
x_tmp = self.activ(x_tmp)
x_tmp = self.fc5(x_tmp)
return x_tmp
grad
fc0.weight tensor(0.5457, device='cuda:0')
grad
fc0.bias tensor(0.0125, device='cuda:0')
grad
fc1.weight tensor(1.2233, device='cuda:0')
grad
fc1.bias tensor(-0.0308, device='cuda:0')
grad
fc2.weight tensor(0.8118, device='cuda:0')
grad
fc2.bias tensor(-0.0240, device='cuda:0')
grad
fc3.weight tensor(-0.4713, device='cuda:0')
grad
fc3.bias tensor(-0.0634, device='cuda:0')
grad
fc4.weight tensor(0.0935, device='cuda:0')
grad
fc4.bias tensor(0.0649, device='cuda:0')
grad
fc5.weight tensor(0.0414, device='cuda:0')
grad
fc5.bias tensor(-0.0463, device='cuda:0')
tensor(1., device='cuda:0')
no grad
conv_in.weight None
no grad
conv_in.bias None
no grad
conv11.weight None
no grad
conv11.bias None
no grad
conv12.weight None
no grad
conv12.bias None
no grad
conv13.weight None
no grad
conv13.bias None
no grad
conv14.weight None
no grad
conv14.bias None
grad
You are detaching c from the computation graph by wrapping it into the deprecated Variable class in:
c = Variable(c, requires_grad=True)
Remove this line of code and it should work.
