Oh, wait…now I understand your task: Given the information about a subject, you want to predict a sequence in operations. So subj_info is the input and operation_series is your target.
In terms of sequence-to-sequence tasks, this is a one-to-many task: one input subj_info, sequence of outputs (operation_series). Basically similar to image caption generation. Or like speech recognition; see the slide below:
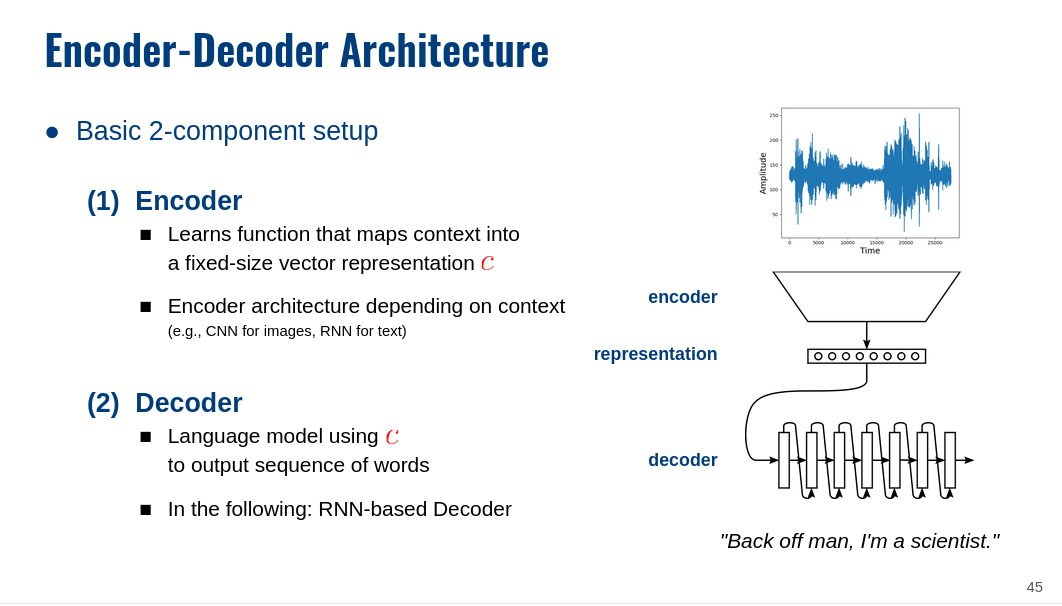
So you basically need some encoder that converts subj_info into some internal representation, and use this representation as the initial hidden state for the LSTM decoder.
The Seq2Seq tutorial gives a good idea how to set this up. The only difference is that in your case the input is not a sequence but just your subj_info, so the encoder will look even simpler.