Hi all,
Following with my last post, I am now trying to concatenate the flattened output of a CNN with another tensor, in the forward pass through the network.
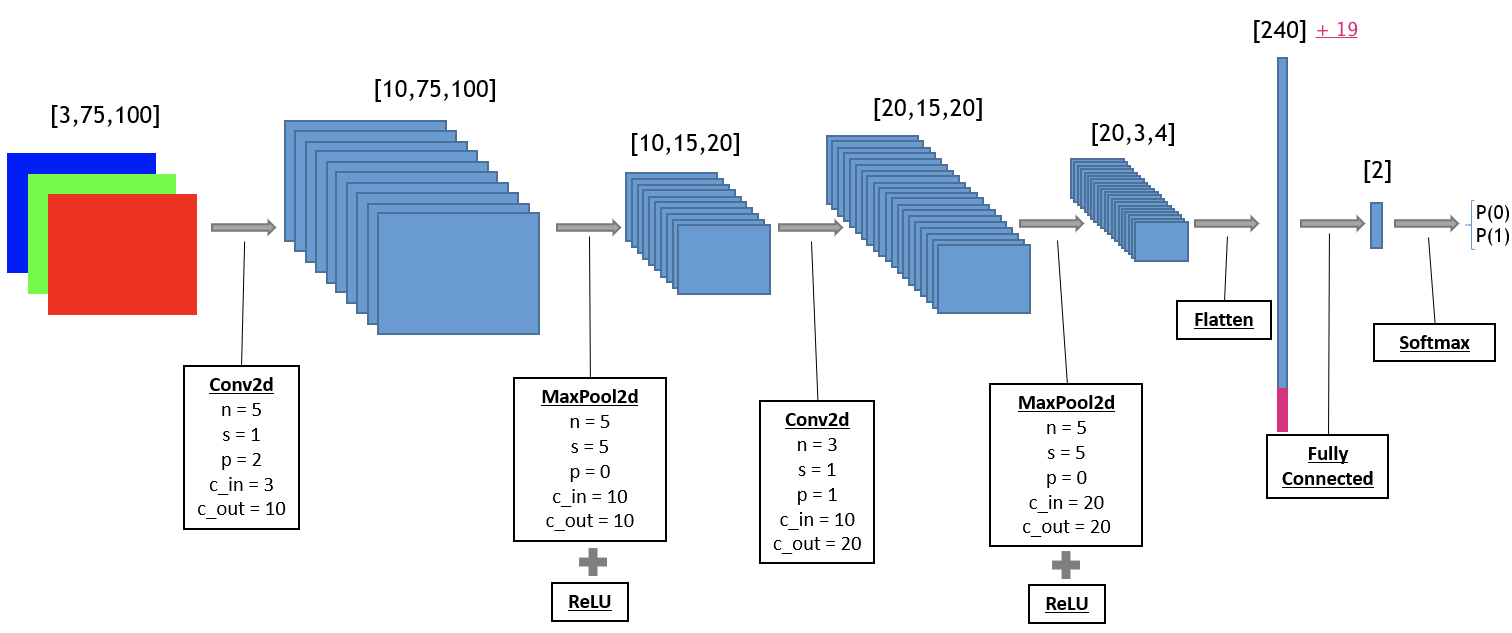
The pink area is the tensor that is to be concatenated to the flattened output.
My CNN is defined as such:
#defining the model with an object oriented approach
from torch import nn, cuda
from torch.nn import functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
#defining convolutional kernels
self.conv1 = nn.Conv2d(3, 10, kernel_size=5, stride=1, padding=2)
self.conv2 = nn.Conv2d(10, 20, kernel_size=3, stride=1, padding=1)
#defining linear layer
self.fc1 = nn.Linear(259, 2)
#defining maxpool
self.pool = nn.MaxPool2d(2, 2)
#defining activation function
self.leaky = nn.LeakyReLU()
def forward(self, x, attributes):
#passing through conv1
x = self.pool(self.leaky(self.conv1(x)))
#passing through conv2
x = self.pool(self.leaky(self.conv2(x)))
#flattening the low level representation of the image
x = x.view(x.size(0), -1)
#merging resulting flattened vector with incoming attributes vector
x = torch.cat((x, attributes), 1)
#passing (batch_size, 259) through linear layer and logsoftmax (to obtain probability scores)
x = nn.LofSoftmax(self.fc1(x))
return x
My training loop so far is defined as follows:
#training loop
for i in range(500):
#iterating through data, one batch at a time, for the 2 data loaders
model.train()
train_loss = 0.0
valid_loss = 0.0
for b, b_2 in zip(mini_b, mini_b2):
#unpacking image (x) and label(y) from b
b_x, b_y = b
#element 0 of b_2 is the attributes associated to b_x
b_2 = b_2[0]
print(b_2.shape)
optimizer.zero_grad()
output = model(b_x, b_2)
loss = criterion(output, b_y)
loss.backward()
optimizer.step()
train_loss += loss.item()
Where mini_b and mini_b2 are 2 data loader objects of the same length. The pink tensor comes from mini_b2 (b_2 in the loop above).
Getting the following error:
TypeError: conv2d(): argument ‘input’ (position 1) must be Tensor, not module