following is the definition of torch.addmm 's parameters: torch.addmm ( beta=1 , mat , alpha=1 , mat1 , mat2 , out=None ) → Tensor
from torch — PyTorch 2.1 documentation
but under it there is an example:
M = torch.randn(2, 3)
mat1 = torch.randn(2, 3)
mat2 = torch.randn(3, 3)
torch.addmm(M, mat1, mat2)
tensor([[-4.8716, 1.4671, -1.3746],
[ 0.7573, -3.9555, -2.8681]])
the call of torch.addmm in the example only uses 3 parameters, when addmm’s last 2 parameters don’t heve a default value.
This is all my confusion about it.
What the M does is to add the random number generated by the 2 by 3 matrix while the mat1 and mat2 are multiply together
that
it will add mat1 and mat2 and multiply the final matrix by M
and the M rep the mat in the addmm
But what I see from pytorch doc is that " torch.addmm( beta=1 , mat , alpha=1 , mat1 , mat2 , out=None )" in which M,mat1 and mat2 should be seen as beta, mat and alpha. I run the example on my pc, it just works as you say, but I don’t understand why it works. Please cure my confusion. Thanks
I know what torch.addmm does. But I don’t know how it can be like this.
let me take an example. why torch.addmm(1,M,1,mat1,mat2) and torch.addmm(M,mat1,mat2) can work the same? why the M in the second call can be parsed as mat instead of beta while the M in the second call is the first parameter? Please forgive my English…
To my knowledge, the non-default parameter can’t follow the default parameter in python. And I’m also confused about the definition of addmm in pytoch doc, where the mat follows the beta=1. And this question is closely related to what we talk about.
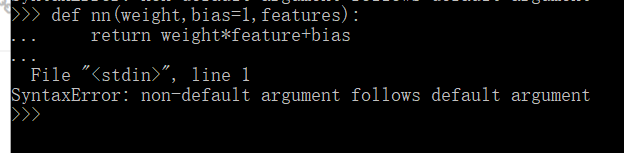
so if you use the function note the bias in the function is given a default value 1 so it allow u to input weight and features without worring about bias except u want to change bias
What happens here is that the addmm does have “overloads” to implement the behaviour that, as you correctly note, would not be possible using a single plain Python function.
The twist is that the one using keyword only alpha and beta arguments is the preferred one (defined in aten/src/ATen/native/native_functions.yaml) while the others are deprecated (defined in tools/autograd/deprecated.yaml).
It is, perhaps, unfortunate that the addmm example uses parameters that are marked as deprecated.
Best regards
Thomas
(who looked at this way too much when generating typehints )
Though I can’t understand the content in the link, it’s enough for me to know the the definition isn’t what’s shown in pytorch doc. Thank you vvvvery much!
 )
)