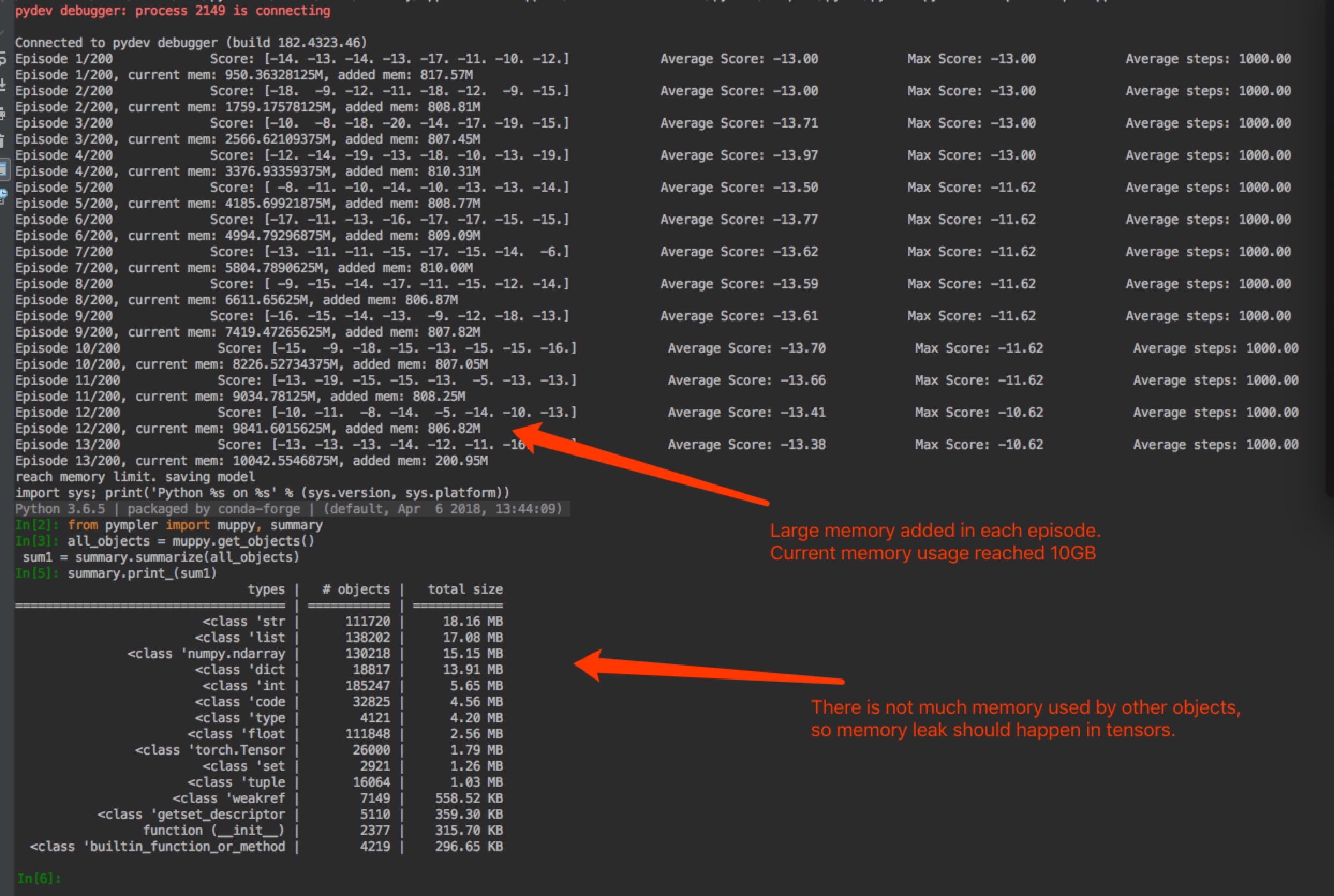
I am experiencing memory leak in my PongDeterministicV4 PPO experiments. I can recreate the constant memory increasing issue with the half-way saved model easily, but I could not be able to locate the issue. With brand new start, the memory start to increase significantly after 100 episodes. I tried pympler tool and it looked to me that the memory used by other objects are ok.
If you run the training with half-way saved model, you will be able to get 10GB memory usage within 15 episodes.
The repository is here - https://github.com/weicheng113/PongPPO
I will paste the screenshots next. I spent a week trying to locate the issue, but have not got any luck yet. Thanks in advance.
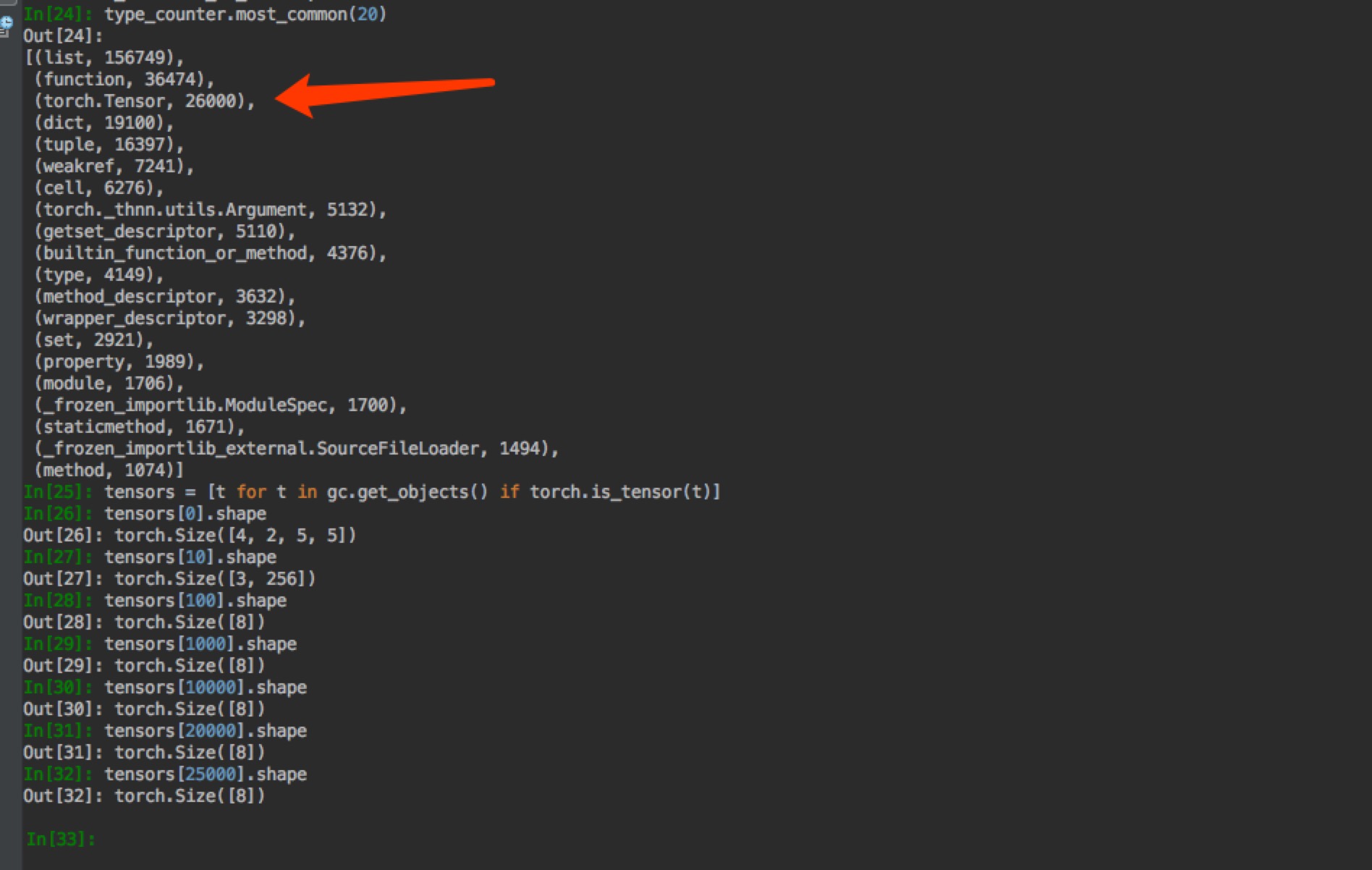
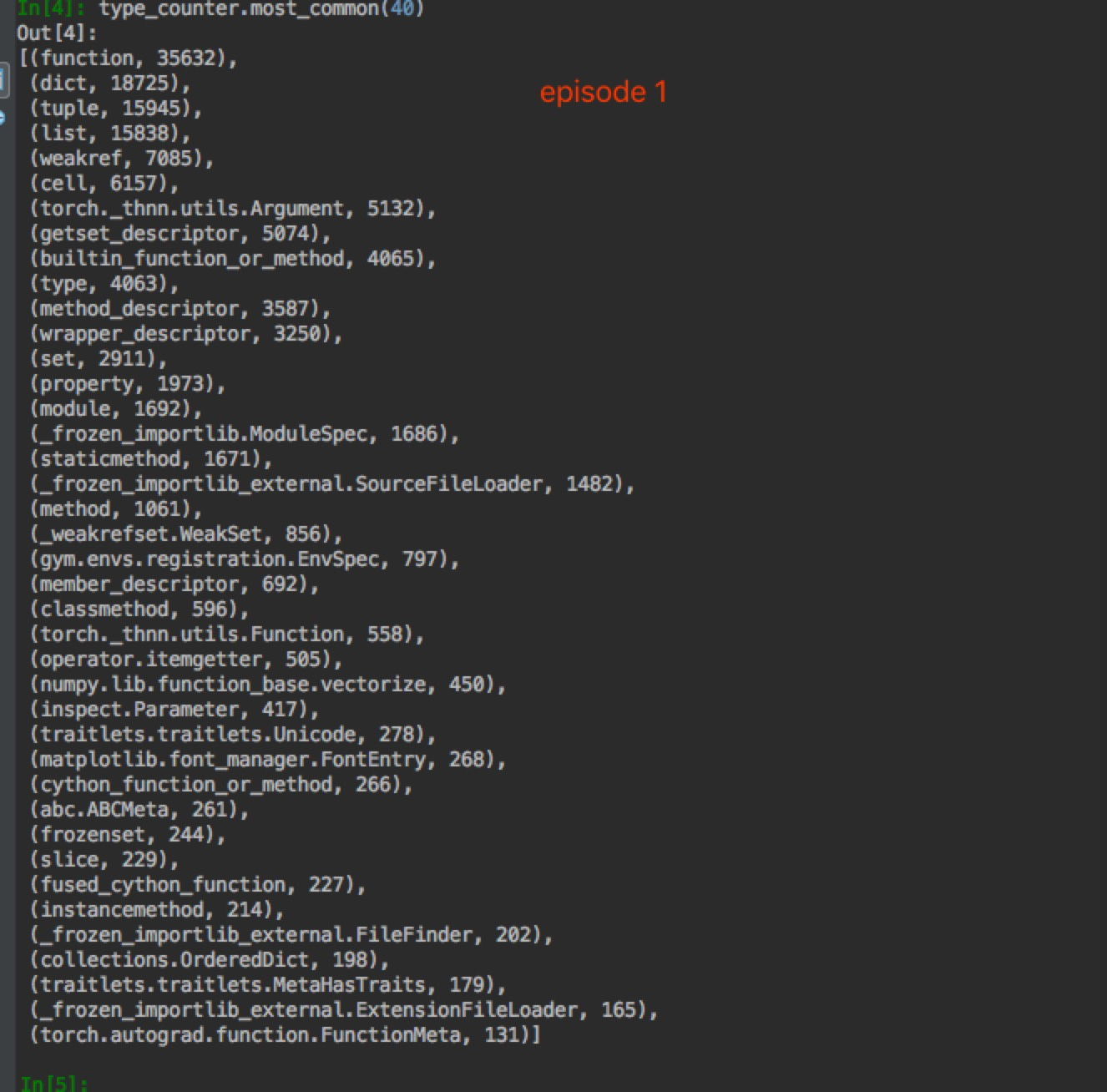
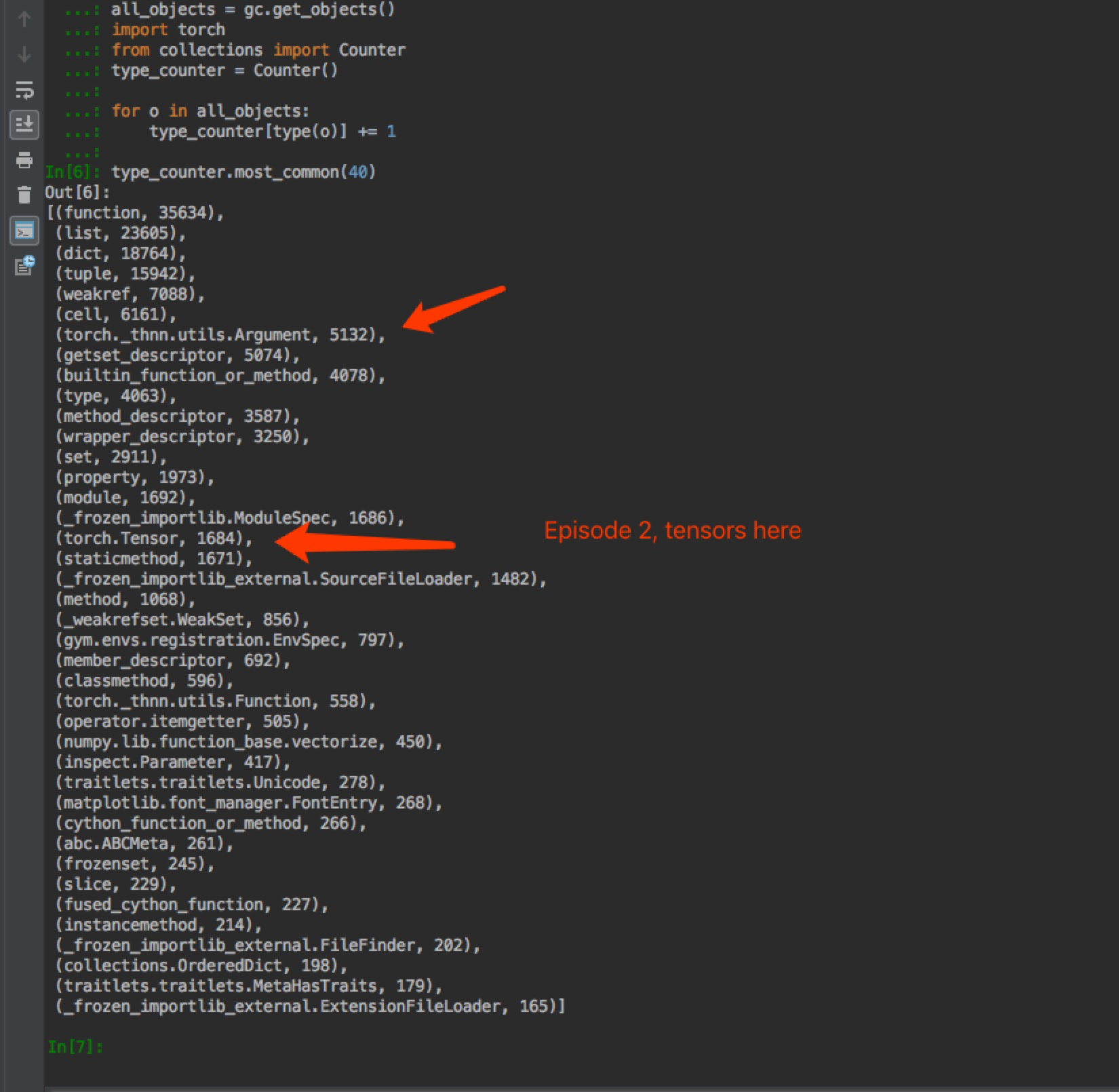
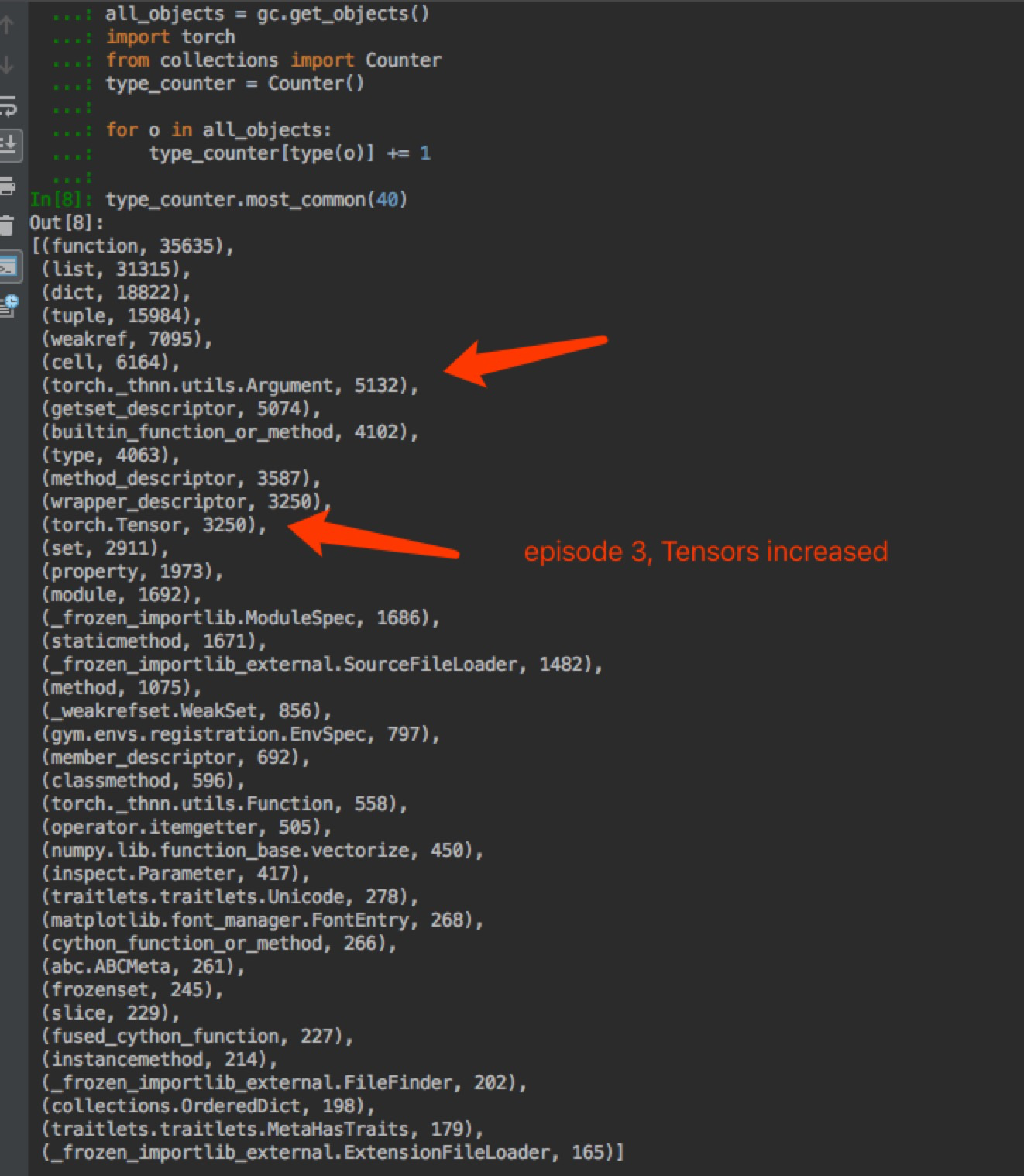
Just tried to train freshly and count different object increment. I can see the number of tensors increased significantly over time. The most use of tensors is in ppo_agent.py - https://github.com/weicheng113/PongPPO/blob/master/ppo_agent.py. It is a simple file, only containing a few lines of code. I could not see any suspicious mis-use of tensors.
I’m not familiar with the code and I’m not sure, which method is called how often, but in the file you’ve linked there is a function which adds tensors to lists: line of code.
Could you check somehow, if and when the clear function is called?
If the tensors are added to the lists, your memory will grow continuously.
It’s usually a good idea to post code directly, as this makes the search easier in the forum in case someone else has a similar issue. You can post code using three backticks `
@ptrblck, It was my mistake. I cut episode by t_max=1000. After some time, as the agent is getting more intelligent, they all don’t get done after 1000 steps. see the code comment on ‘if np.any(dones): // no one has dones after some time.’. So it will not enter learning step after time, and self.parallel_trajectory keeps accumulating.
def step(self, i_episode, states, actions, action_probs, rewards, next_states, dones):
self.parallel_trajectory.add(
parallel_states=states,
parallel_actions=actions,
parallel_action_probs=action_probs,
parallel_rewards=rewards,
parallel_next_states=next_states,
parallel_dones=dones)
if np.any(dones): **// no one has dones after some time.**
states, actions, action_probs, rewards, next_states, dones = self.parallel_trajectory.numpy()
returns = self.parallel_trajectory.discounted_returns(self.discount)
states_tensor, actions_tensor, action_probs_tensor, returns_tensor, next_states_tensor = self.to_tensor(
states=states,
actions=actions,
action_probs=action_probs,
returns=returns,
next_states=next_states)
self.learn(
states=states_tensor,
actions=actions_tensor,
action_probs=action_probs_tensor,
returns=returns_tensor,
next_states=next_states_tensor)
del self.parallel_trajectory
self.parallel_trajectory = ParallelTrajectory(n=self.num_parallels)