I want to change the code in this link
into pytorch framework
I start working on this but I don’t know how I will convert lmdb datasets to pytorch tensor without error to start creating (new model and train the datasets) and also using pre-trained model that used in this link
this is my code
from google.colab import drive
drive.mount(‘/content/drive’)
import torch
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from torchvision.utils import make_grid
from torch.utils.data.dataloader import DataLoader
from torch.utils.data import random_split
%matplotlib inline
from future import print_function
import os
import cv2
import json
import lmdb
import torch
import numpy as np
from matplotlib import pyplot
class USCISI_CMD_API( object ) :
“”" Simple API for reading the USCISI CMD dataset
This API simply loads and parses CMD samples from LMDB
# Example:
```python
# get the LMDB file path
lmdb_dir = os.path.dirname( os.path.realpath(__file__) )
# create dataset instance
dataset = USCISI_CMD_API( lmdb_dir=lmdb_dir,
sample_file=os.path.join( lmdb_dir, 'samples.keys'),
differentiate_target=True )
# retrieve the first 24 samples in the dataset
samples = dataset( range(24) )
# visualize these samples
dataset.visualize_samples( samples )
# retrieve 24 random samples in the dataset
samples = dataset( [None]*24 )
# visualize these samples
dataset.visualize_samples( samples )
# get the exact 50th sample in the dataset
sample = dataset[50]
# visualize these samples
dataset.visualize_samples( [sample] )
```
# Arguments:
lmdb_dir = file path to the dataset LMDB
sample_file = file path ot the sample list, e.g. samples.keys
differentiate_target = bool, whether or not generate 3-class target map
# Note:
1. samples, i.e. the output of "get_samples" or "__call__", is a list of samples
however, the dimension of each sample may or may not the same
2. CMD samples are generated upon
- MIT SUN2012 dataset [https://groups.csail.mit.edu/vision/SUN/]
- MS COCO dataset [http://cocodataset.org/#termsofuse]
3. detailed synthesis process can be found in paper
# Citation:
Yue Wu et.al. "BusterNet: Detecting Image Copy-Move ForgeryWith Source/Target Localization".
In: European Conference on Computer Vision (ECCV). Springer. 2018.
# Contact:
Dr. Yue Wu
yue_wu@isi.edu
"""
def __init__( self, lmdb_dir, sample_file,train_file,valid_file,test_file, differentiate_target = True ) :
assert os.path.isdir(lmdb_dir)
self.lmdb_dir = lmdb_dir
assert os.path.isfile(sample_file)
self.sample_keys = self._load_sample_keys(sample_file)
#add train,valid and test files and load the keys of them
assert os.path.isfile(train_file)
self.train_keys = self._load_train_keys(train_file)
assert os.path.isfile(valid_file)
self.valid_keys = self._load_valid_keys(valid_file)
assert os.path.isfile(test_file)
self.test_keys = self._load_test_keys(test_file)
self.differentiate_target = differentiate_target
print("INFO: successfully load USC-ISI CMD LMDB with {} keys".format( self.nb_samples ) )
print("INFO: It have {} train keys".format( len( self.train_keys ) ) )
print("INFO: It have {} validation keys".format( len( self.valid_keys ) ) )
print("INFO: It have {} test keys".format( len( self.test_keys ) ) )
def __len__(self):
return len( self.sample_keys )
@property
def nb_samples( self ) :
return len( self.sample_keys )
def _load_sample_keys( self, sample_file ) :
'''Load sample keys from a given sample file
INPUT:
sample_file = str, path to sample key file
OUTPUT:
keys = list of str, each element is a valid key in LMDB
'''
with open( sample_file, 'r' ) as IN :
keys = [ line.strip() for line in IN.readlines() ]
return keys
#new methods
def _load_train_keys( self, train_file ) :
'''Load sample keys from a given sample file
INPUT:
sample_file = str, path to sample key file
OUTPUT:
keys = list of str, each element is a valid key in LMDB
'''
with open( train_file, 'r' ) as IN :
train_keys = [ line.strip() for line in IN.readlines() ]
return train_keys
def _load_valid_keys( self, valid_file ) :
'''Load sample keys from a given sample file
INPUT:
sample_file = str, path to sample key file
OUTPUT:
keys = list of str, each element is a valid key in LMDB
'''
with open( valid_file, 'r' ) as IN :
valid_keys = [ line.strip() for line in IN.readlines() ]
return valid_keys
def _load_test_keys( self, test_file ) :
'''Load sample keys from a given sample file
INPUT:
sample_file = str, path to sample key file
OUTPUT:
keys = list of str, each element is a valid key in LMDB
'''
with open( test_file, 'r' ) as IN :
test_keys = [ line.strip() for line in IN.readlines() ]
return test_keys
def _get_image_from_lut( self, lut ) :
'''Decode image array from LMDB lut
INPUT:
lut = dict, raw decoded lut retrieved from LMDB
OUTPUT:
image = np.ndarray, dtype='uint8'
'''
image_jpeg_buffer = lut['image_jpeg_buffer']
image = cv2.imdecode( np.array(image_jpeg_buffer).astype('uint8').reshape([-1,1]), 1 )
image = cv2.resize(image, (128,128), interpolation = cv2.INTER_AREA)
return image
def _get_mask_from_lut( self, lut ) :
'''Decode copy-move mask from LMDB lut
INPUT:
lut = dict, raw decoded lut retrieved from LMDB
OUTPUT:
cmd_mask = np.ndarray, dtype='float32'
shape of HxWx1, if differentiate_target=False
shape of HxWx3, if differentiate target=True
NOTE:
cmd_mask is encoded in the one-hot style, if differentiate target=True.
color channel, R, G, and B stand for TARGET, SOURCE, and BACKGROUND classes
'''
def reconstruct( cnts, h, w, val=1 ) :
rst = np.zeros([h,w], dtype='uint8')
cv2.fillPoly( rst, cnts, val )
return rst
h, w = lut['image_height'], lut['image_width']
src_cnts = [ np.array(cnts).reshape([-1,1,2]) for cnts in lut['source_contour'] ]
src_mask = reconstruct( src_cnts, h, w, val = 1 )
tgt_cnts = [ np.array(cnts).reshape([-1,1,2]) for cnts in lut['target_contour'] ]
tgt_mask = reconstruct( tgt_cnts, h, w, val = 1 )
if ( self.differentiate_target ) :
# 3-class target
background = np.ones([h,w]).astype('uint8') - np.maximum(src_mask, tgt_mask)
cmd_mask = np.dstack( [tgt_mask, src_mask, background ] ).astype(np.float32)
else :
# 2-class target
cmd_mask = np.maximum(src_mask, tgt_mask).astype(np.float32)
cmd_mask = cv2.resize(cmd_mask, (128,128), interpolation = cv2.INTER_AREA)
return cmd_mask
def _get_transmat_from_lut( self, lut ) :
'''Decode transform matrix between SOURCE and TARGET
INPUT:
lut = dict, raw decoded lut retrieved from LMDB
OUTPUT:
trans_mat = np.ndarray, dtype='float32', size of 3x3
'''
trans_mat = lut['transform_matrix']
return np.array(trans_mat).reshape([3,3])
def _decode_lut_str( self, lut_str ) :
'''Decode a raw LMDB lut
INPUT:
lut_str = str, raw string retrieved from LMDB
OUTPUT:
image = np.ndarray, dtype='uint8', cmd image
cmd_mask = np.ndarray, dtype='float32', cmd mask
trans_mat = np.ndarray, dtype='float32', cmd transform matrix
'''
# 1. get raw lut
lut = json.loads(lut_str)
# 2. reconstruct image
image = self._get_image_from_lut(lut)
# 3. reconstruct copy-move masks
cmd_mask = self._get_mask_from_lut(lut)
# 4. get transform matrix if necessary
trans_mat = self._get_transmat_from_lut(lut)
return ( image, cmd_mask, trans_mat )
def get_one_sample( self, key = None ) :
'''Get a (random) sample from given key
INPUT:
key = str, a sample key or None, if None then use random key
OUTPUT:
sample = tuple of (image, cmd_mask, trans_mat)
'''
return self.get_samples([key])[0]
def get_samples( self, key_list ) :
'''Get samples according to a given key list
INPUT:
key_list = list, each element is a LMDB key or idx
OUTPUT:
sample_list = list, each element is a tuple of (image, cmd_mask, trans_mat)
'''
env = lmdb.open( self.lmdb_dir )
sample_list = []
with env.begin( write=False ) as txn :
for key in key_list :
if not isinstance( key, str ) and isinstance( key, int ):
idx = key % self.nb_samples
key = self.sample_keys[idx]
elif isinstance( key, str ) :
pass
else :
key = np.random.choice(self.sample_keys, 1)[0]
print("INFO: use random key", key)
lut_str = txn.get( key.encode(encoding='utf-8', errors='strict') )
sample = self._decode_lut_str( lut_str )
sample_list.append( sample )
return sample_list
def visualize_samples( self, sample_list ) :
'''Visualize a list of samples
'''
for image, cmd_mask, trans_mat in sample_list :
pyplot.figure(figsize=(10,10))
pyplot.subplot(121)
pyplot.imshow( image )
pyplot.subplot(122)
pyplot.imshow( cmd_mask )
return
def pytorch_tensor_samples( self, sample_list ) :
'''Visualize a list of samples
'''
i=0
All_samples = {}
for image, cmd_mask, trans_mat in sample_list :
pytorchTensorSample = torch.tensor([image,cmd_mask])
pytorchTensorTrans_mat=torch.tensor(trans_mat)
#pytorchTensorTrans_mat=pytorchTensorTrans_mat.reshape(-1,3,3)
print(pytorchTensorSample.shape)
print(pytorchTensorTrans_mat.shape)
All_samples[i] =[pytorchTensorSample,pytorchTensorTrans_mat]
i = i + 1
return All_samples
def __call__( self, key_list ) :
return self.get_samples( key_list )
def __getitem__( self, key_idx ) :
return self.get_one_sample( key=key_idx )
import sys
lmdb_dir = ‘/content/drive/MyDrive/Full dataset/USCISI-CMFD’
sys.path.insert(0,lmdb_dir)
dataset = USCISI_CMD_API( lmdb_dir=lmdb_dir,
sample_file=os.path.join( lmdb_dir, ‘samples.keys’),
train_file=os.path.join( lmdb_dir, ‘train.keys’),
valid_file=os.path.join( lmdb_dir, ‘valid.keys’),
test_file=os.path.join( lmdb_dir, ‘test.keys’ ),
differentiate_target=True )
def simple_cmfd_decoder( busterNetModel, rgb ) :
“”“A simple BusterNet CMFD decoder
“””
# 1. expand an image to a single sample batch
single_sample_batch = np.expand_dims( rgb, axis=0 )
# 2. perform busterNet CMFD
pred = busterNetModel.predict(single_sample_batch)[0]
return pred
def visualize_result( rgb, gt=None, pred=None, figsize=(12,4), title=None ) :
“”“Visualize raw input, ground truth, and BusterNet result
“””
pyplot.figure( figsize=figsize )
pyplot.subplot(131)
pyplot.imshow( rgb )
pyplot.title(‘input image’)
if gt is not None :
pyplot.subplot(132)
pyplot.title(‘ground truth’)
pyplot.imshow(gt)
if pred is not None :
pyplot.subplot(133)
pyplot.imshow(pred)
pyplot.title(‘busterNet pred’)
if title is not None :
pyplot.suptitle( title )
for k in range(10) :
rgb, gt, trans_mat = dataset.get_one_sample()
#pred = simple_cmfd_decoder( busterNetModel, rgb )
visualize_result( rgb, gt)
sample = dataset[100]
visualize these samples
dataset.visualize_samples( [sample] )
sample = dataset[0]
sample1 = dataset[1]
convert samples to pytorch tensor
pTensor= dataset.pytorch_tensor_samples([sample,sample1])
print(pTensor[0][0].shape)
print(pTensor[1][0].shape)
print(type(dataset))
from torch.utils.data import random_split
val_size = 10000
test_size = 10000
train_size = 80000
train_ds, val_ds, test_ds = random_split(dataset, [train_size, val_size, test_size])
len(train_ds), len(val_ds), len(test_ds)
from torch.utils.data import DataLoader
batch_size=64
train_loader = DataLoader(train_ds, batch_size, shuffle=True)
test_loader = DataLoader(test_ds, batch_size2)
val_loader = DataLoader(val_ds, batch_size2)
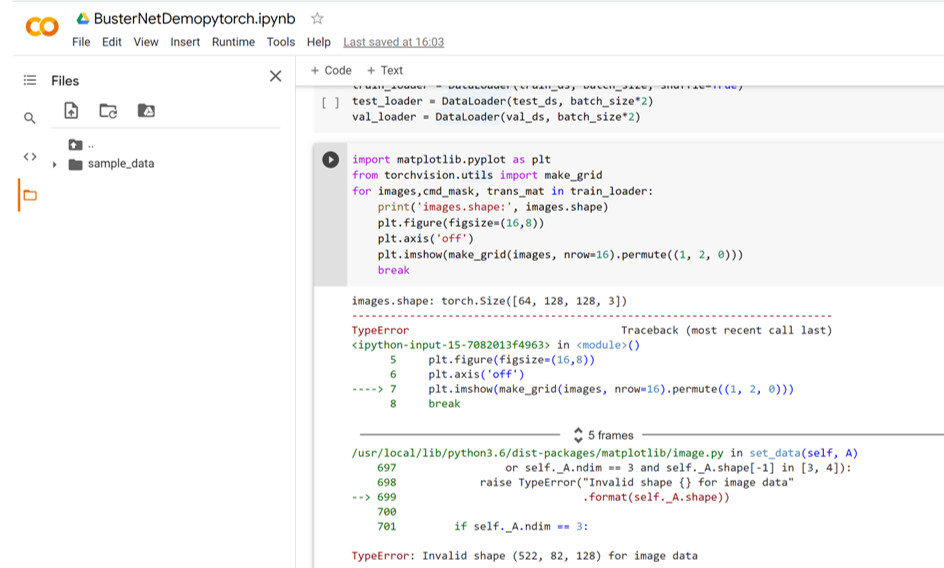
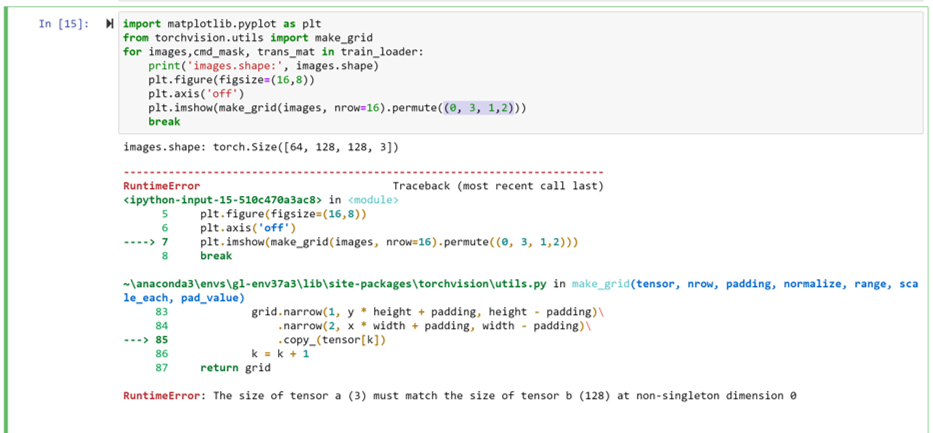
import matplotlib.pyplot as plt
from torchvision.utils import make_grid
for images,cmd_mask, trans_mat in train_loader:
print(‘images.shape:’, images.shape)
plt.figure(figsize=(16,8))
plt.axis(‘off’)
plt.imshow(make_grid(images, nrow=16).permute((1, 2, 0)))
break
I don’t know if my starting is correct or not, also I found the following error