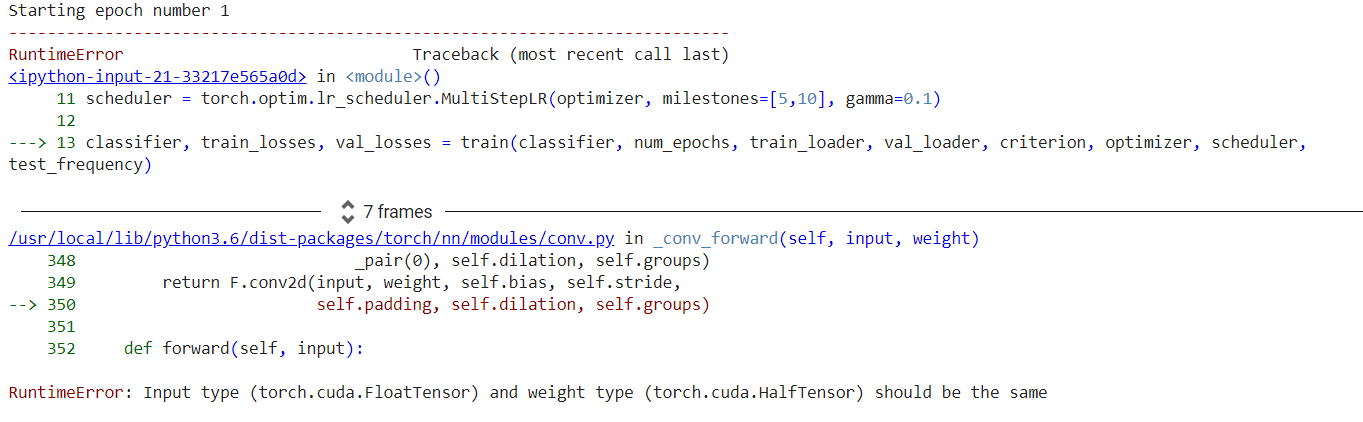
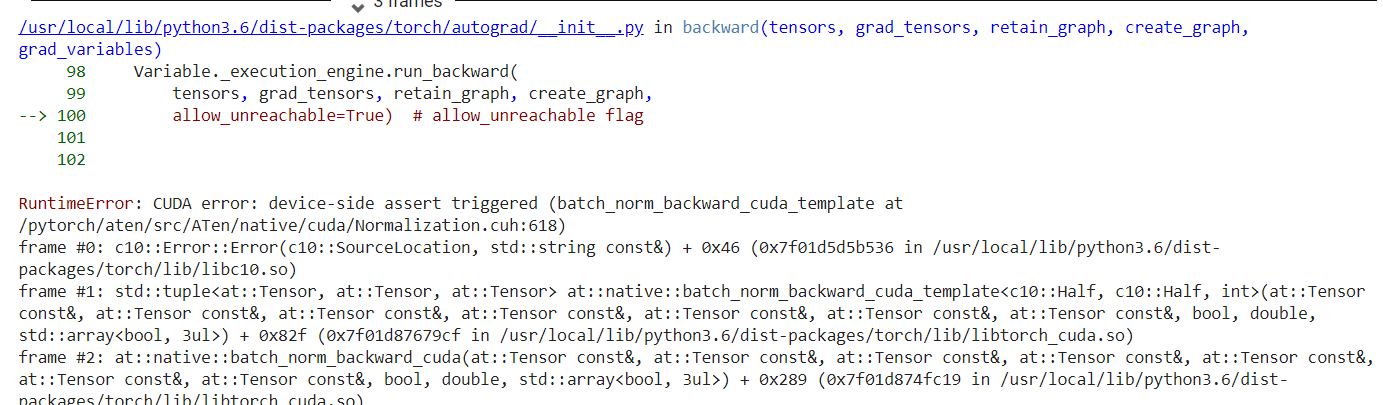
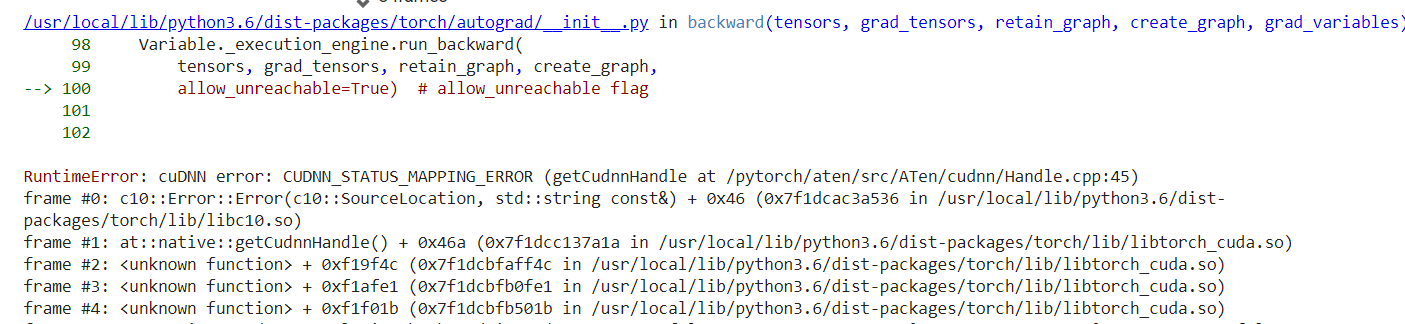
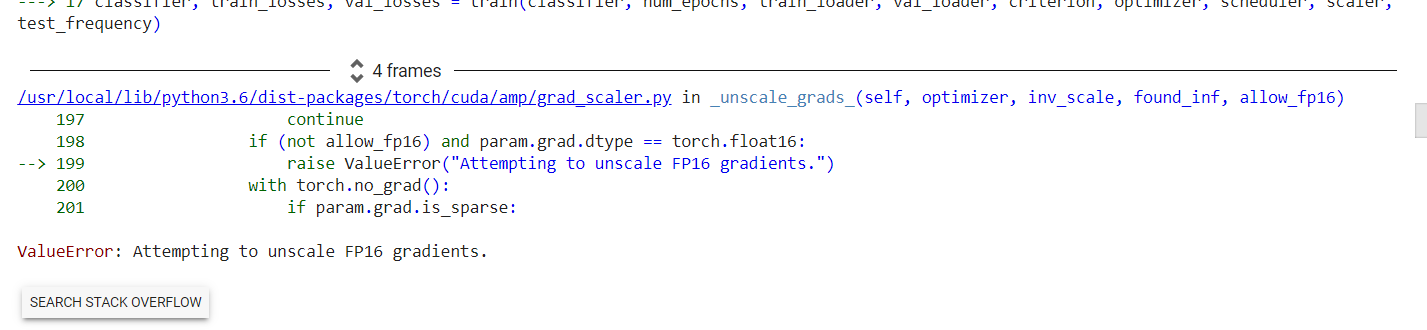
Variables are deprecated since PyTorch 0.4 so you can use tensors now.
Could you post an executable code snippet using random tensors, so that we could reproduce the issue and debug further?
I guess the second error might be raised since you are converting the model to half and back to float() after again during the training, which could cause dtype mismatches.
Could you explain your use case of converting the model back and forth and, if possible, post an executable code snippet as simple models (e.g. resnet18) seem to work?
Since this the first time I am trying to convert the model to half precision, so I just followed the post below. And it was converting the model to float and half, back and forth, so I thought this is the correct way.
But I am getting error even on the first epoch if I remove don’t convert back the model back to float. The modified code looks like:
def train_classifier(classifier, train_loader, optimizer, criterion):
classifier.half()
classifier.train()
loss = 0.0
losses = []
for i, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.float().to(device)
images = images.half()
optimizer.zero_grad()
logits = classifier(images)
logits = logits.float()
loss = criterion(logits, labels)
loss = loss.float()
loss.backward()
optimizer.step()
losses.append(loss)
return torch.stack(losses).mean().item()
I would still recommend to use the automatic mixed-precision in case you want a stable FP16 training, where numerical sensitive operations are automatically performed in FP32.
Could you still post the model definition and an executable code snippet to reproduce the issue, since I’m unable to run into this error using standard torchvision models.
Thanks for the update.
If I run your code snippet, I get invalid outputs after two iterations since the model is overflowing, which is creating an error in the criterion and thus a CUDA assert failure:
Could you update to the latest stable version (.1.7.0) and retry importing it? torch.cuda.amp.autocast was introduced in 1.6.0, but I would recommend to use the latest version, since it ships with the latest bug fixes and additional features.
I am able to run the auto-cast by the loss is causing an issue, my code looks like:
with torch.cuda.amp.autocast():
logits = classifier(images)
loss = criterion(logits, labels)
And I am getting an error on loss calculation. The error mentions that I should use some other loss function other that BCELoss, but I need to have a sigmoid layer just before the output, so what kind of loss should I use as the pytorch is recommending me to use loss with logits.
Or is there some way to make it work.
Your model should return the raw logits and you should use nn.BCEWithLogitsLoss as the criterion.
If you want to see the probabilities, you could still apply torch.sigmoid to them, but don’t pass them to the loss function.
I am using the code below to convert the model into mixed precision. And I have also commented the sigmoid line but still I am facing the issue.
for i, (images, labels) in enumerate(train_loader):
images, labels = images.float().to(device), labels.float().to(device)
optimizer.zero_grad()
with torch.cuda.amp.autocast():
logits = classifier(images)
loss = criterion(logits, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
But I am getting the error on line scaler.scale(loss).backward(). I am getting the following error: