A paper I am reading now proposes an architecture to do classification on EEG data and it looks like the following (Note this diagram is sufficient for implementation and no other details in the paper are relevant).
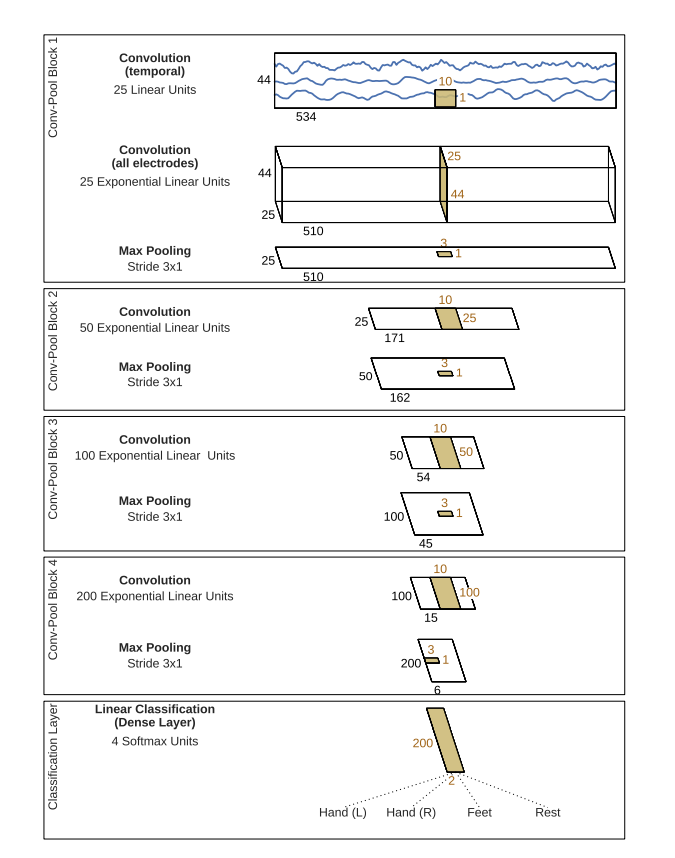
But when I tried to implement this architecture, I got two issues
- In Conv-Pool Block 1, the second convolution seems to do convolution on (C, H) instead of (H, W) and I do not know how to do this using
torch.nn.Conv2d(). - In Conv-Pool Block 2-4, it seems that the convolution is always operated on (C, 1, W) and every time I finish convolution, I need to permute the output to make convolution doable, which is a little weird for me. Say, in Conv-Pool Block 2, in order to convolve (batchSize, 25, 1, 171) with filter (25, 10), I need to permute it into (batchSize, 1, 25, 171) and I will get (batchSize, 50, 1, 162).
So did I understand this diagram correctly? Any input will be appreciated.