Hi,
This problem is slowing down my research, any help appreciated! I’m on pytorch 0.4.
I’m copy’ing an LSTM state to a new graph location where I want it’s data to be copied into indices of a torch.nn.Parameter(). I was detaching at first, but now I’m doing: cell_state.data.cpu(). I have a shared torch.nn.Module() living on the cpu that has two Parameter()'s. I’m copying into to shared module’s Parmeter()'s like so:
shared_module.shared_param[idx, :].copy_(cell_state.data.cpu())
Is there anything wrong with this? Something in rnnFusedPointwise is growing by 588 bytes every rollout/backprop:
================================== Begin Trace:
/home/joe/Documents/tools/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/_functions/thnn/rnnFusedPointwise.py:74: size=44.2 KiB (+588 B), count=1576 (+21), average=29 B
.../rlresearch.pytorch/src/utils.py:116: size=784 B (-72 B), count=5 (-1), average=157 B
.../pytorch/lib/python3.6/site-packages/torch/_thnn/utils.py:108: size=7968 B (-70 B), count=93 (-1), average=86 B
.../pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py:607: size=13.3 KiB (+0 B), count=167 (+0), average=81 B
.../pytorch/lib/python3.6/site-packages/torch/nn/_functions/rnn.py:30: size=11.4 KiB (+0 B), count=66 (+0), average=176 B
.../pytorch/lib/python3.6/site-packages/torch/_thnn/utils.py:26: size=9248 B (+0 B), count=1 (+0), average=9248 B
.../pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py:704: size=8160 B (+0 B), count=15 (+0), average=544 B
.../rlresearch.pytorch/src/models/base.py:67: size=7416 B (+0 B), count=21 (+0), average=353 B
.../pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py:764: size=4536 B (+0 B), count=9 (+0), average=504 B
.../pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py:610: size=4318 B (+0 B), count=58 (+0), average=74 B
================================== Begin Trace:
.../pytorch/lib/python3.6/site-packages/torch/nn/_functions/thnn/rnnFusedPointwise.py:74: size=44.7 KiB (+588 B), count=1597 (+21), average=29 B
.../rlresearch.pytorch/src/utils.py:116: size=856 B (+72 B), count=6 (+1), average=143 B
.../pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py:607: size=13.3 KiB (+0 B), count=167 (+0), average=81 B
.../pytorch/lib/python3.6/site-packages/torch/nn/_functions/rnn.py:30: size=11.4 KiB (+0 B), count=66 (+0), average=176 B
.../pytorch/lib/python3.6/site-packages/torch/_thnn/utils.py:26: size=9248 B (+0 B), count=1 (+0), average=9248 B
.../pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py:704: size=8160 B (+0 B), count=15 (+0), average=544 B
.../pytorch/lib/python3.6/site-packages/torch/_thnn/utils.py:108: size=7968 B (+0 B), count=93 (+0), average=86 B
.../rlresearch.pytorch/src/models/base.py:67: size=7416 B (+0 B), count=21 (+0), average=353 B
.../pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py:764: size=4536 B (+0 B), count=9 (+0), average=504 B
.../pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py:610: size=4318 B (+0 B), count=58 (+0), average=74 B
Background Info:
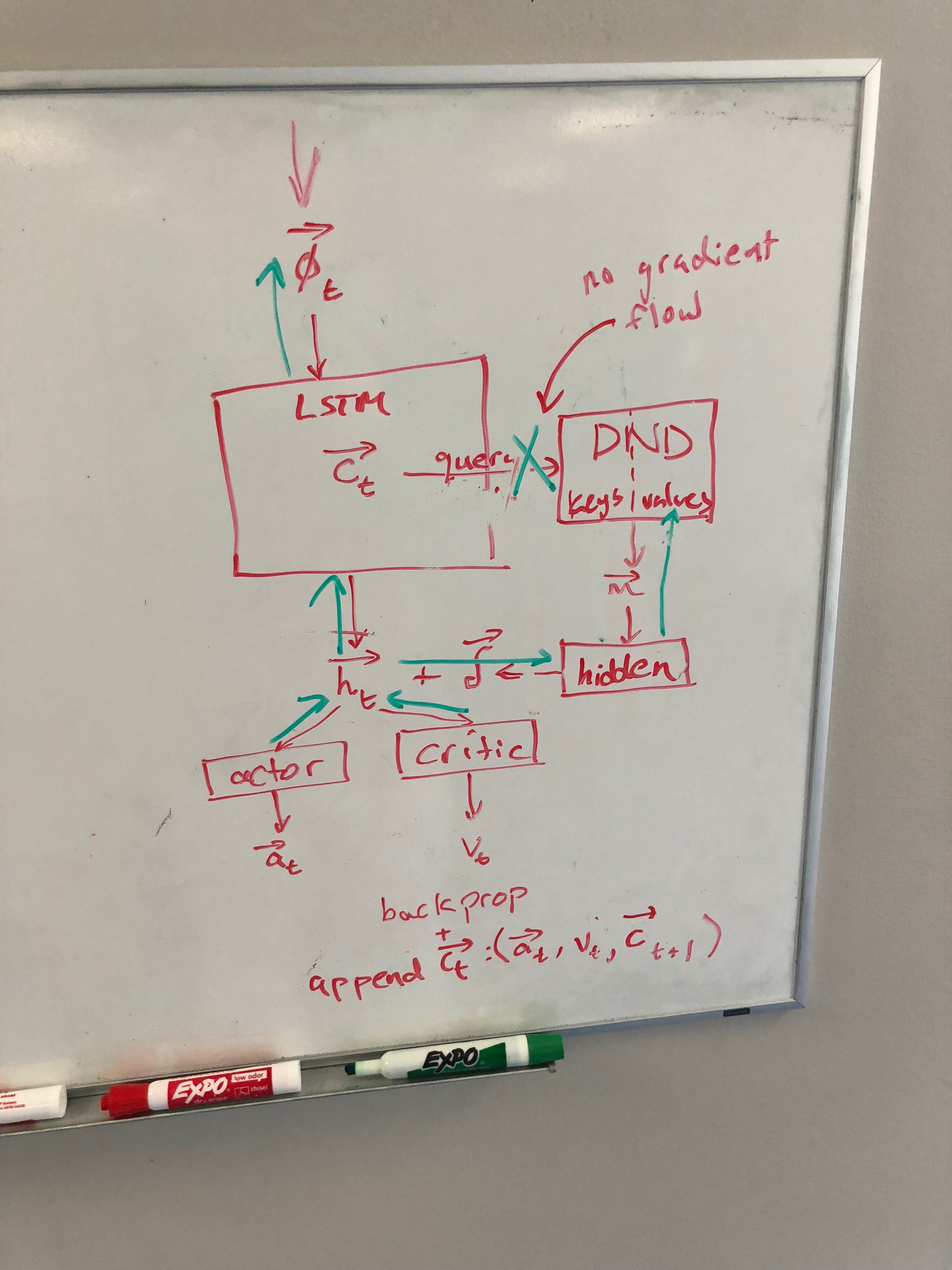
I’m trying to add a long-term memory to my reinforcement learning agent. Without the long-term memory, everything works with no leaks. The long-term memory is a Differentiable Neural Dictionary (DND). I simplified the implementation a lot and used fixed size parameter tensors instead of unbounded lists as used in the paper. The implementation is fairly straightforward.
I have multiple GPU worker processes that have a shared model and a shared DND long-term memory that live on the CPU. The long-term memory stores the agent’s LSTM cell-state as the keys and cat(action, value, next cell state) as value. Every inference step, the agent’s cell state is queried for similar cell states and values are returned as a similarity-weighted vector.
Life of a worker (https://github.com/jtatusko/rlresearch.pytorch/blob/dnd/src/workers/recalling.py):
- L54-L55 Each worker updates it’s GPU model and long-term memory from a snapshot of the CPU model and long-term memory.
- L60-L71 Each worker performs n steps (20 by default) with the environment and saves all relevant information for backprop in a rollout cache.
- L73-L77 All memories are .data.cpu()'ed before being added to the long-term memory write cache.
- L88 At the end of the rollout, the rollout_cache is processed to get losses and losses are backprop’ed.
- L109 Model gradients are sync’ed to the CPU model
- L110 DND gradients are sync’ed to the CPU DND
- L111 Optimizer (CPU) steps
- L114-L117 Long-term memory write cache is processed and written to the CPU’s DND. Everything in the cache has already been .data.cpu()'ed from Step 4. Worker’s can’t write into the same index because the index is shared across the workers and sync’ed with a torch.multiprocessing.Lock().