Hello,
I’m trying to experiment different configuration with the A3C code posted on GitHub under the following link:
https://github.com/MorvanZhou/pytorch-A3C
All my tested are concerned with the script “discrete_A3C.py”
https://github.com/MorvanZhou/pytorch-A3C/blob/master/discrete_A3C.py
Python Version: 3.6.9
Torch Version: 1.4.0
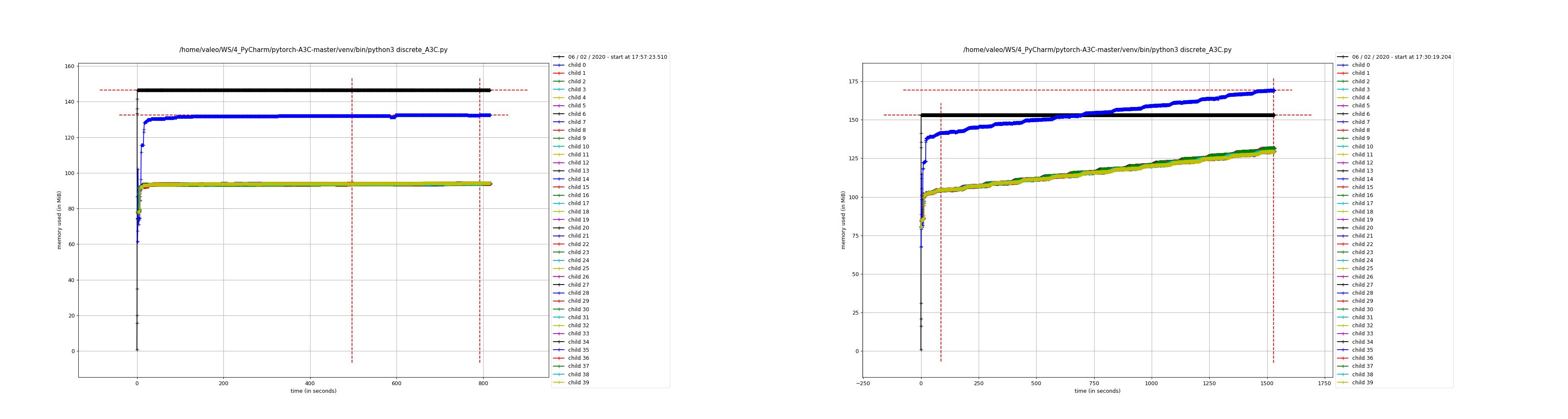
If I keep everything as in the original code the memory usage is consistent and does not increase over time. Which can be shown by plotting the memory usage graph using the command:
mprof run --multiprocess discrete_A3C.py
However, I tried to change the NN architecture to be as follows:
def __init__(self, s_dim, a_dim):
super(Net, self).__init__()
self.s_dim = s_dim
self.a_dim = a_dim
self.fc1 = nn.Linear(s_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.pi1 = nn.Linear(128, 64)
self.pi2 = nn.Linear(64, a_dim) # Q values for each action are output
self.v1 = nn.Linear(128, 128)
self.v2 = nn.Linear(128, 1)
set_init([self.pi1, self.pi2, self.fc1, self.fc2, self.v1, self.v2])
self.distribution = torch.distributions.Categorical
def forward(self, x):
x = F.relu6(self.fc1(x))
x = F.relu6(self.fc2(x))
pi1 = F.relu6(self.pi1(x))
logits = self.pi2(pi1)
v1 = F.relu6(self.v1(x))
values = self.v2(v1)
return logits, values
re-running the same command as before however it can be noticed a linear increase of memory usage overtime.
Please check the image below where the figure on the left is from running the original code, and the figure on the right is from the modified architecture.
I tried to debug this myself during the past week but can not come up with any clues, if anyone can provide any insights would be of valuable help.

