I have a sequece labeling task.
So as input, I have a sequence of elements with shape [batch_size, sequence_length] and I need to assign a class for each element of a sequence.
And as a loss function, I use a Cross-entropy.
How should I correctly use it?
My variable target_predictions has shape [batch_size, sequence_length, number_of_classes] and target has shape [batch_size, sequence_length]
Documentation says:
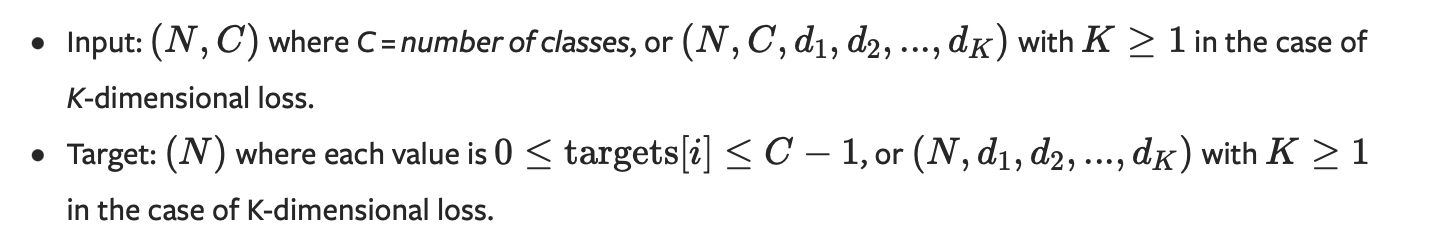
I know if I use CrossEntropyLoss(target_predictions.permute(0, 2, 1), target), everything will work fine. But I have concerns that in case of k-dimensional loss, torch will intepret my sequence_length as d_1 as on screenshot.
How should I correctly do it?