I am trying to use CRNN, model to give me Text-Perceptual-Loss, to be used for Text Super Resolution.
I am using pyotrch’s CTC loss,
criterion = nn.CTCLoss(blank=0)
def encode_text_batch(text_batch):
text_batch_targets_lens = [len(text) for text in text_batch]
text_batch_targets_lens = torch.IntTensor(text_batch_targets_lens)
text_batch_concat = "".join(text_batch)
text_batch_targets = []
for c in text_batch_concat:
try:
if (c=='"' ):
id = char2id["'"]
else:
id =char2id[c]
text_batch_targets.append(id)
except:
text_batch_targets.append(0)
text_batch_targets = torch.IntTensor(text_batch_targets)
#print(text_batch_targets)
return text_batch_targets, text_batch_targets_lens
def compute_loss(text_batch, text_batch_logits):
"""
text_batch: list of strings of length equal to batch size
text_batch_logits: Tensor of size([T, batch_size, num_classes])
"""
print(text_batch_logits.shape)
text_batch_logps = F.log_softmax(text_batch_logits, 2) # [T, batch_size, num_classes]
#print(text_batch_logps.shape)
#print(text_batch_logps.size(0))
text_batch_logps_lens = torch.full(size=(text_batch_logps.size(1),),
fill_value=text_batch_logps.size(0),
dtype=torch.int32).to(device) # [batch_size]
#print(text_batch_logps_lens)
#print(text_batch_logps.shape)
#print(text_batch_logps_lens)
text_batch_targets, text_batch_targets_lens = encode_text_batch(text_batch)
#print(text_batch_targets,text_batch_targets_lens)
#print(text_batch_targets_lens)
loss = criterion(text_batch_logps, text_batch_targets, text_batch_logps_lens, text_batch_targets_lens)
return loss
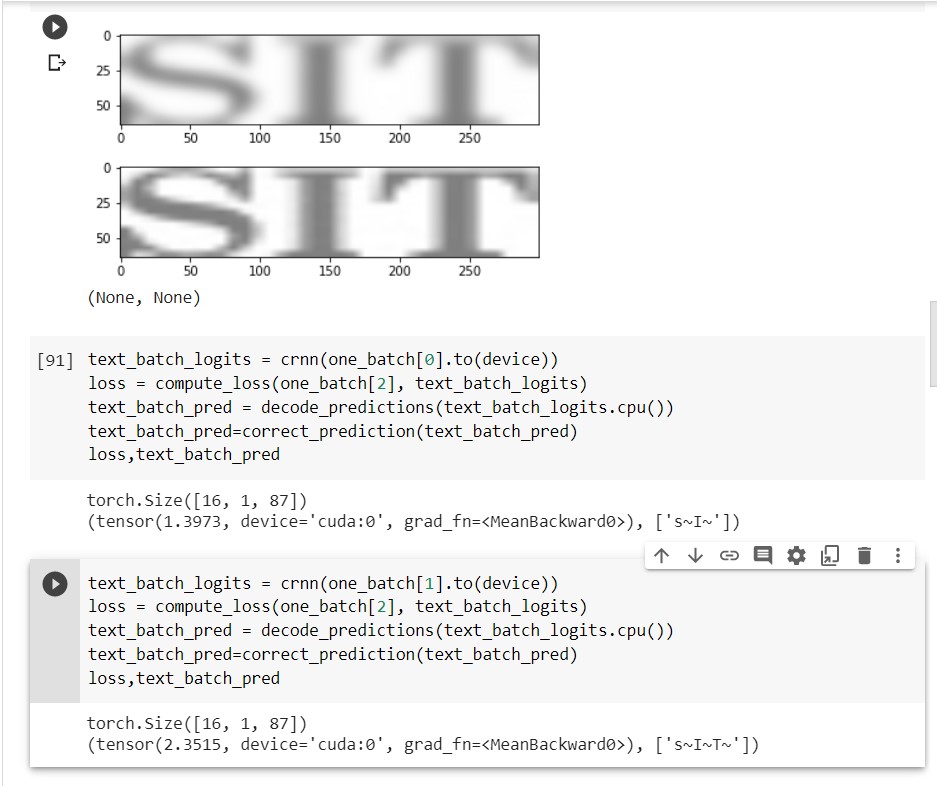
But, like for image-example I am sharing, for “SIT”, if it is predicting SI, loss is less, AS COMPARED TO WHEN IT PREDICTS "SIT
"
Kindly, help me with this.
Thanks alot