Works! Was not so familiar with DataParallel…
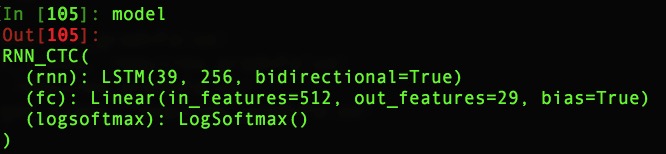
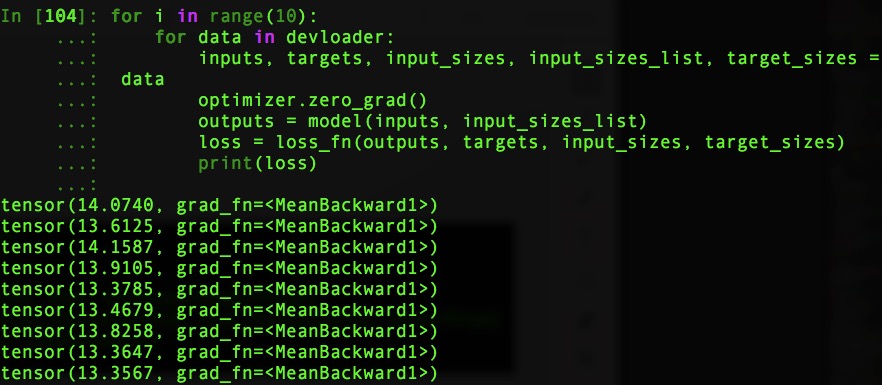
Hi! I also work in ASR project. Now I am building a ASR system by using CTCLoss. However, the loss doesn’t converge. My model and the loss of every iteration are showing in the following picture. May you guys help me check the problem? Thanks.
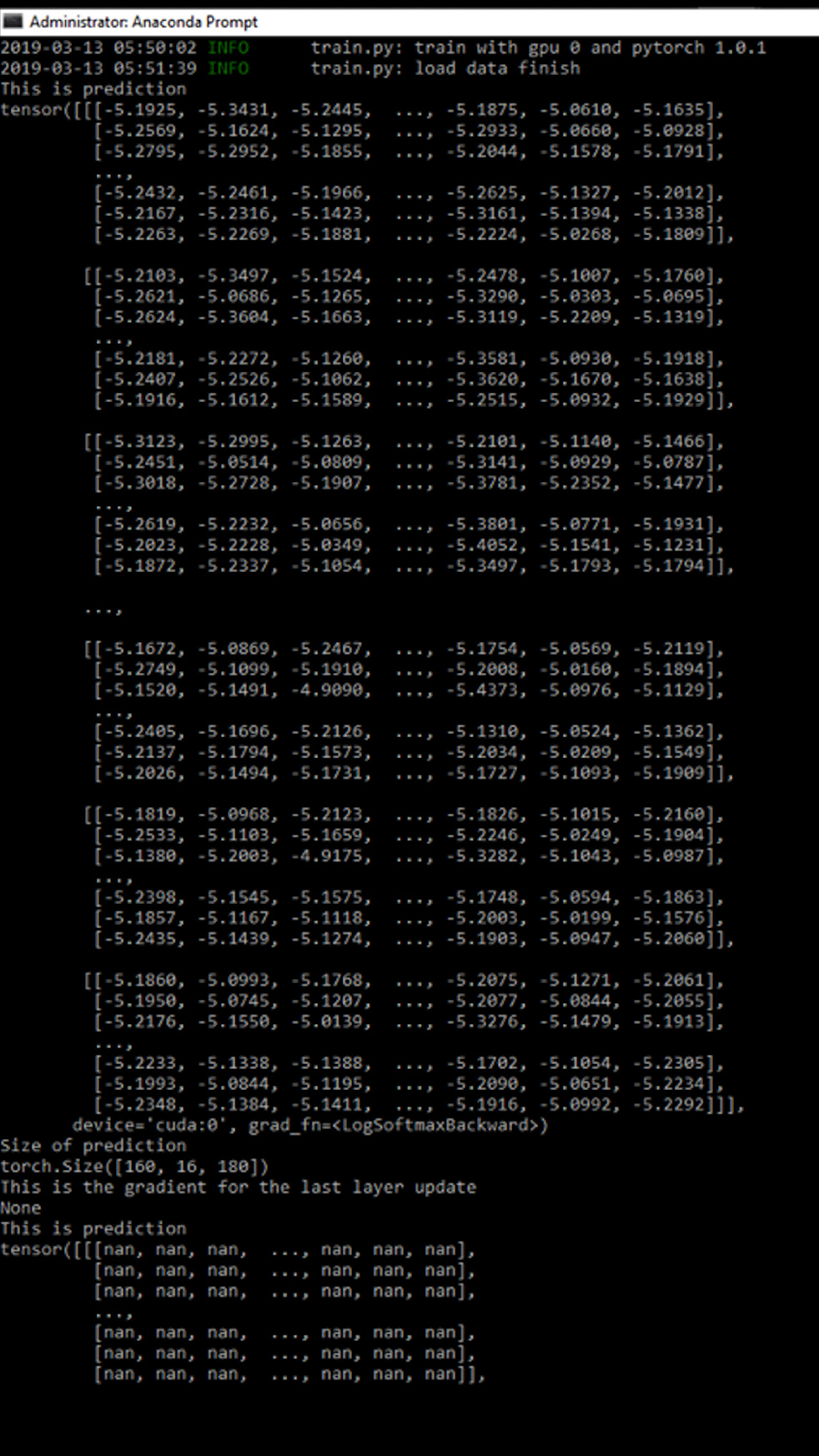
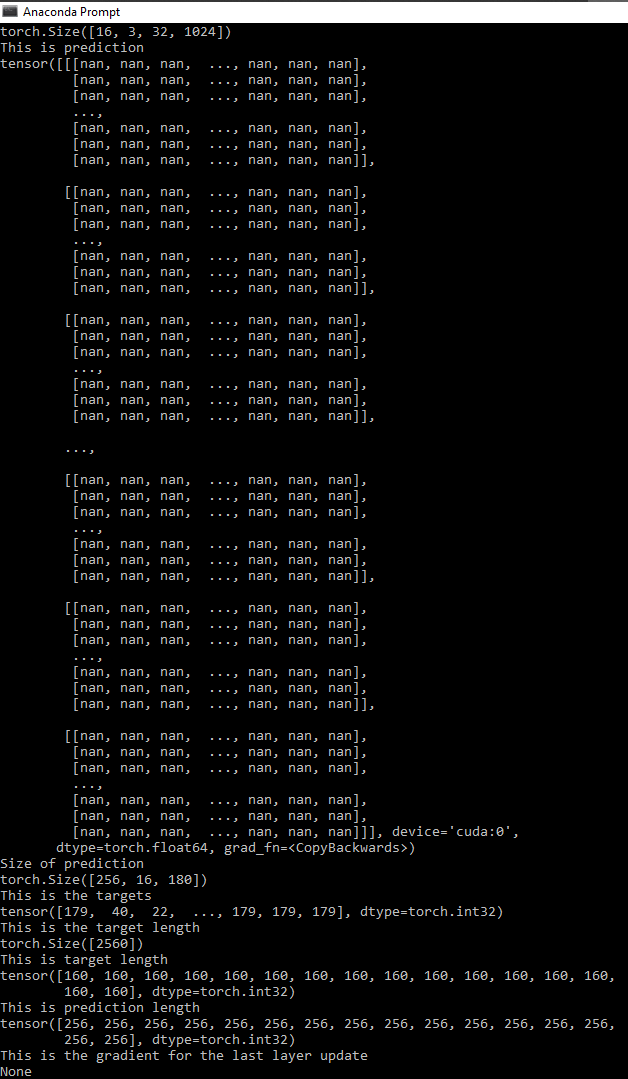
Hello. I’ve been training a CRNN for a text recognition task by referencing @jun_zhou and meijieru’s repositories for my term paper. To prevent cases like input length being less than the targets length, I resized the images of the training text images to 3 x 32 x 640 dimensions. The max number of character that can be present in the image is 160 so after a number of convolutional layers, I made sure that the resulted feature map is 2048 x 1 x 160 dimensions. The total number of output classes is 180 so the final output from the CRNN model is 160 x 16 x 180 matrix. However, in training process, the ctc loss immediately becomes nan after the very first epoch. It seems to be that the gradient for the predictions become nan. I’ve been debugging the code if I had any implementation errors for a long time but still I can’t find it. Can you help me please?
Here is the training code.
try:
for epoch in range(start_epoch + 1, config.epochs):
model.train()
if float(scheduler.get_lr()[0]) > config.end_lr:
scheduler.step()
start = time.time()
batch_acc = .0
batch_loss = .0
cur_step = 0
for i, (images,labels) in enumerate(train_data_loader):
cur_batch_size = images.size(0)
# print(cur_batch_size)
targets, targets_lengths = converter.encode(labels)
# converter returns python list data structure so
# convert them back to torch tensor
targets = torch.Tensor(targets)
targets_lengths = torch.Tensor(targets_lengths)
images = images.to(device)
# Now make the prediction
preds = model(images)
# print(preds.size())
preds = preds.log_softmax(2)
preds_lengths = torch.Tensor([preds.size(0)] * cur_batch_size)
loss = criterion(preds, targets, preds_lengths, targets_lengths) # text, preds_size must be cpu
# do back propagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss = loss.item() / cur_batch_size
acc = accuracy(preds.cpu(), labels, preds_lengths.cpu(), converter) / cur_batch_size
batch_acc += acc
batch_loss += loss
# write tensorboard
cur_step = epoch * all_step + i
writer.add_scalar(tag='ctc_loss', scalar_value=loss, global_step=cur_step)
writer.add_scalar(tag='train_acc', scalar_value=acc, global_step=cur_step)
writer.add_scalar(tag='lr', scalar_value=scheduler.get_lr()[0], global_step=cur_step)
Here is the model code
# Define the convolutional body using Resnet architecture
class ResNet(nn.Module):
def __init__(self, in_channels):
super(ResNet,self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64, momentum=0.9),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2,padding=0),
# nn.Conv2d(in_channels=64,out_channels=64,kernel_size=2, stride=1, bias=False),
# nn.BatchNorm2d(64, momentum=0.9),
# nn.ReLU(),
ResidualBlock(in_channels=64,out_channels=64, stride=1, downsample=True),
ResidualBlock(in_channels=64,out_channels=128, stride=1, downsample=True),
nn.Dropout(0.2),
ResidualBlock(in_channels=128, out_channels=128, stride=2, downsample=True),
ResidualBlock(in_channels=128, out_channels=256, stride=1, downsample=True),
nn.Dropout(0.2),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=2, stride=(2, 1), padding=(0, 1), bias=False),
ResidualBlock(in_channels=256, out_channels=512,stride=1, downsample=True),
nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, padding=0, bias=False),
nn.BatchNorm2d(1024, momentum=0.9),
nn.ReLU(),
nn.Conv2d(in_channels=1024, out_channels=2048, kernel_size=2, padding=(0, 1), bias=False),
nn.BatchNorm2d(2048, momentum=0.9),
nn.ReLU()
)
def forward(self, x):
return self.features(x)
# Define BiLSTM for language Modelling
class BidirectionalLSTM(nn.Module):
def __init__(self, in_channels, hidden_size, num_layers):
super(BidirectionalLSTM,self).__init__()
self.rnn = nn.LSTM(input_size=in_channels, hidden_size=hidden_size,num_layers=num_layers, bidirectional=True)
def forward(self, x):
x,_ = self.rnn(x)
return x
class FeatureExtractor(nn.Module):
def __init__(self,in_channels):
super(FeatureExtractor,self).__init__()
self.cnn = ResNet(in_channels=in_channels)
def forward(self, x):
return self.cnn(x)
class LanguageModeller(nn.Module):
def __init__(self,in_channels, n_class, hidden_size, num_layers):
super(LanguageModeller,self).__init__()
self.rnn = nn.Sequential(
BidirectionalLSTM(in_channels=in_channels, hidden_size=hidden_size, num_layers=num_layers),
BidirectionalLSTM(in_channels=hidden_size * 2, hidden_size=hidden_size, num_layers=num_layers)
)
self.fc = nn.Linear(hidden_size * 2, n_class)
def forward(self, x):
x = self.rnn(x)
x = self.fc(x)
return x
class CRNN(nn.Module):
def __init__(self, in_channels, n_class, hidden_size, num_layers=1):
super(CRNN,self).__init__()
self.feature_extractor = FeatureExtractor(in_channels)
self.languagemodeller = LanguageModeller(2048, n_class, hidden_size, num_layers)
def forward(self, x):
x = self.feature_extractor(x)
x = x.squeeze(dim=2)
x = x.permute(2,0,1)
x = self.languagemodeller(x)
return x
Here is the output result:
Here is the sample data
![]()
you can change preds = preds.log_softmax(2) to
preds = preds.log_softmax(2).to(torch.flaot64).
this is work in my dataset
Htut Lynn Aung via PyTorch Forums noreply@discuss.pytorch.org 于2019年3月13日周三 下午2:06写道:
I converted the prediction tensor of the model into torch.float64 but still nothing is changed. The loss and prediction of the model immediately becomes nan in second batch(not even at the epoch level). To solve this problem, I tried making the feature map of the convolutional model part result in more length from former 3 x 32 x 160 tensor into 3 x 32 x 356 tensor so that the prediction_lengths would be sufficiently greater than target_length. for the first batch, the model still output some values but starting from second epoch everything starts to began ‘nan’. I am kinda stuck in this particular bug.
prediction for first batch
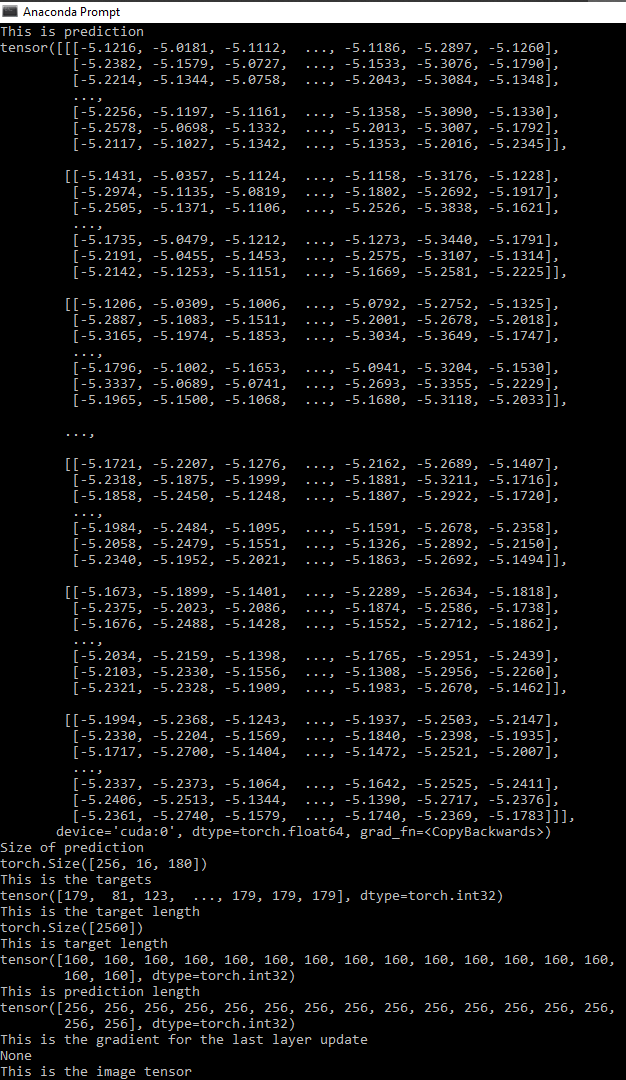
prediction for second batch
I am stuck in exactly the same problem. Did you solve the problem? I need help in this problem.
The trick is to use the zero_infinity=True option of PyTorch 1.1.
Where should i add this parameter?
You can add it when you call the constructor:
criterion = torch.nn.CTCLoss(zero_infinity=True)
this parameter is not supported in my torch.nn.CTCLoss
That was introduced with PyTorch 1.1.
Still doesn’t work, loss got nan after some batches with torch.nn.CTCLoss(zero_infinity=True).
So far, about everyone else in that situation had something else that was funny with their setup.
Best regards
Thomas
I did some debugging in the last few days. I have summarized my observation in https://github.com/pytorch/pytorch/pull/21244 and provide a stopgap solution.
Also, from my observation, NaN only happens at large batches/seq length (see the condition at https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/LossCTC.cu#L552). In my case, my input length is around 1K (ASR). If I disable the is_large check, no NaN. So I am wondering could everyone in this thread to share whether they will hit is_large condition to help debug ?
Note that NaN is not infinity, so before we find out the exact root cause, I think we should zero out NaN in gradient.
During the review of https://github.com/pytorch/pytorch/pull/21244 , we track down a real bug in the original implementation (thanks for @tom pushing me back on diving into the root cause) – some elements in beta tensor are not properly initialized, thus possible creating NaN or widely large floating point numbers indeterminstically. #21244 is thus abandoned in favor of #21392 which should solve this issue. I have run several experiments for a while, all of them are running in a good state.
If you still observe numerical issue in CTCLoss, please feel free to comment on this thread (or contact me and the original author @tom of course).
@tom, I have two questions about the current CTC implementation in PyTorch.
1: Is there any reason Eq 16 from the CTC paper https://www.cs.toronto.edu/~graves/icml_2006.pdf is used as opposed to Eq 7.29 from Graves’ PhD https://www.cs.toronto.edu/~graves/phd.pdf? Note that there is a difference of y^t_k in the second term.
2: Regarding the gradient that is computed inside CTCLoss, is it the gradient with respect to the logits or the gradient with respect to the logsoftmax probabilities? Do these computed gradients get backproped through the logsoftmax layer?
I’m also interested in Pytorch version of keras.ctc_decode
@tom
Why do target indices outside of [1, C] not lead to an inf-loss or an error?
What happens under the hood?
Example snippet modified:
T = 50 # Input sequence length
C = 20 # Number of classes (including blank)
N = 16 # Batch size
S = 30 # Target sequence length of longest target in batch
S_min = 10 # Minimum target length, for demonstration purposes
input = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
# target indices outside of [1, C]
target = torch.randint(low=-10, high=-1, size=(N, S), dtype=torch.long)
input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
target_lengths = torch.randint(low=S_min, high=S, size=(N,), dtype=torch.long)
ctc_loss = nn.CTCLoss()
loss = ctc_loss(input, target, input_lengths, target_lengths)
print(loss)
It works, thanks, and zero_infinty of ctcloss doesn’t work as expected.