Hi everyone,
Can someone explain to me why I need to convert Cuda tensor to tensor.cpu first, and after that to Numpy?
I know how to do it, but I want to know why I should do it.
"TypeError: can’t convert CUDA tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first. "
As far as I understand, and hopefully someone will correct me if I’m wrong:
standard numpy arrays reside only in cpu memory
therefore, a cuda tensor must first be sent to the cpu before it can be converted to numpy
If your question is really ‘why doesn’t calling .numpy on a cuda tensor send it to cpu by default, without the user having to specify?’, I don’t know. Surely there is a technical reason, that hopefully someone else can elaborate. You could of course write your own function to do both in one step, if you really want to avoid writing .cpu().numpy() every time, e.g.:
def cudaToNumpy(cudaTensor):
return cudaTensor.detach().cpu().numpy() #I add a detach in case the tensor has gradients etc
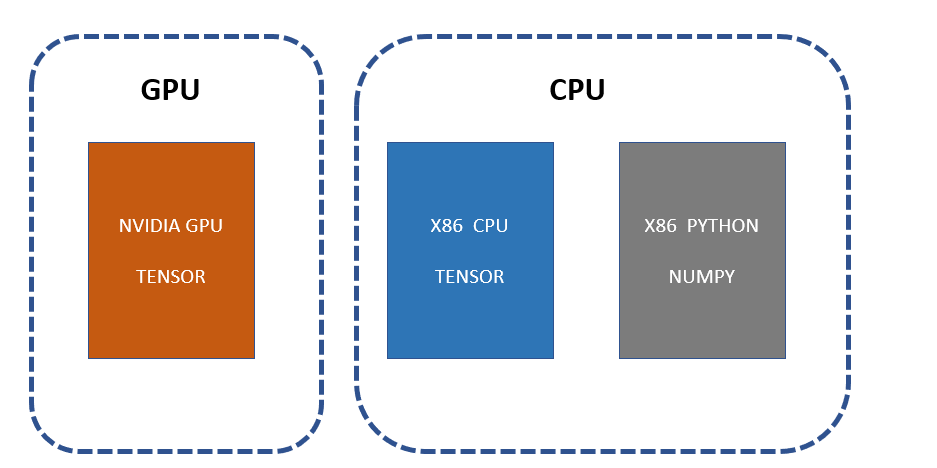
What we need to understand is that in both the two dashes the architecture is very different. What the .cpu() command does is transfers the data into the memory linked to the x86 architecture which can then be leveraged by the numpy libraries. Numpy relies heavily on C which again is linked to the architecture of normal CPUs, hence the direct GPU Tensor to Numpy does not work