Hi, all, when using pytorch for training, I met some problems:

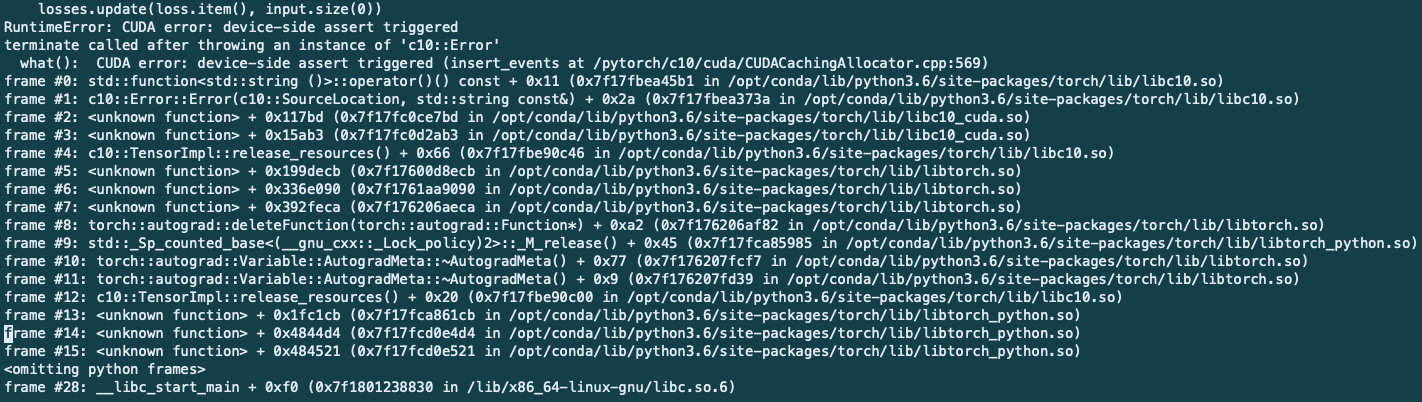
pytorch version: 1.2.0.dev20190715
cuda version: 9.0
gpu: GTX 1080ti.
I’ve spent some time to debug this problem, but failed unfortunately. Hope to get some help here!
Hi, all, when using pytorch for training, I met some problems:
pytorch version: 1.2.0.dev20190715
cuda version: 9.0
gpu: GTX 1080ti.
I’ve spent some time to debug this problem, but failed unfortunately. Hope to get some help here!
Do you see the same error, if you run the code on CPU?
This might yield a clearer error message than the current CUDA one.
If it’s working fine on the CPU, could you rerun the code using
CUDA_LAUNCH_BLOCKING=1 python script.py args
and post the stack trace again?
PS: You can post code directly by wrapping it in three backticks ``` 
See ptrblck’s post for ways to debug the issue. But any reason you’re apparently both using an old nightly of 1.2.0 when 1.2.0 has now been released and also running against CUDA 9.0 when PyTorch is built against 9.2? One of those may well be the cause of the issue.
I’ve tried to rerun the code with “CUDA_LAUNCH_BLOCKING=” before python. Unfortunately, the code couldn’t run into the training process with this flag.
I’ve added “torch.autograd.set_detect_anomaly(True)” into the code, then the error became:
File "/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py", line 539, in __call__
result = self.forward(*input, **kwargs)
File "/opt/conda/lib/python3.6/site-packages/torch/nn/modules/linear.py", line 87, in forward
return F.linear(input, self.weight, self.bias)
File "/opt/conda/lib/python3.6/site-packages/torch/nn/functional.py", line 1365, in linear
ret = torch.addmm(bias, input, weight.t())
Traceback (most recent call last):
File "/workspace/pyface/engine/trainer.py", line 287, in <module>
main(args)
File "/workspace/pyface/engine/trainer.py", line 69, in main
main_worker(args.gpu, ngpus_per_node, args)
File "/workspace/pyface/engine/trainer.py", line 137, in main_worker
do_train(train_loader, model, criterion, optimizer, epoch, args, architect, valid_loader)
File "/workspace/pyface/engine/trainer.py", line 270, in do_train
loss.backward()
File "/opt/conda/lib/python3.6/site-packages/torch/tensor.py", line 118, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/opt/conda/lib/python3.6/site-packages/torch/autograd/__init__.py", line 93, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: Function 'AddmmBackward' returned nan values in its 2th output.
It seems some nan in the grad?
Thanks for your advice, I’ve already changed the pytorch version to 1.2(stable), cuda10.0 cudnn7.6.
The error remains the same.
I found when I run the training with batchsize 1024 on 8 1080 ti gpu cards, it will report the error. When I run the code with batchsize 512 on 8 gpu cards, the error disappeared. when I run the code with smaller batchsize on a single gpu card, the error can’t be reproduced. So it might be hard to reproduce the error on cpu.
Yes, looks like a bug in the PyTorch AddmmBackward causing it to output a nan (or something in the autograd). Unless someone else can see something I’m missing you should probably submit an issue. It all seems to be PyTorch code.
In order to get a reliable reproduction you could try adding code in your training loop to store a reference to the current inputs (making sure to overwrite each batch and not keep old ones around). Then when the error happens you should have the inputs that caused it. You will also want to save the model weights as it will depend on these. Then hopefully you can get a set of inputs and weights that will reliably trigger it.
The real issue is that in topk an invariant condition failed. It would be very useful if you can
CUDA_LAUNCH_BLOCKING=1
topk to a file (you can overwrite in each iteration)Thanks!
Really thanks for the reply. I tried to reproduced the error at another gpu machine using same docker container setting, while found no error occurs. The error may be highly related to a broken 1080ti gpu card, Although the regular checks don’t show the error.